常用bash命令
系统相关
1. hostname - 查看主机名
hostname命令用于查看系统的主机名,或是修改系统的主机名。
hostname的常用命令如下:
# 显示系统的当前主机名
hostname
# 修改你系统的主机名
hostname blinkfox-system
# 使用 -F 选项,从指定的文件中读取主机名
hostname -F /root/hostname.txt2. uptime - 查看系统运行时间
uptime命令用于打印系统的运行时间等信息。使用如下:
uptime查看硬件时间:hwclock --show
查看系统时间:date
系统时间与硬件时间同步
//以系统时间为基准,修改硬件时间
hwclock --systohc<== sys(系统时间)to(写到)hc(Hard Clock)
hwclock -w
//以硬件时间为基准,修改系统时间
hwclock --hctosys
hwclock -s不同机器之间时间同步
ntpdate ip/hostname/domain
3. w、who - 列出登录的用户
w命令用于显示登录用户及他们当前运行的进程。输入的内容格式如下:
w
# 打印如下
22:42 up 18 days, 1 hr, 2 users, load averages: 1.23 1.79 1.75
USER TTY FROM LOGIN@ IDLE WHAT
blinkfox console - 日19 6days -
blinkfox s000 - 五23 - wwho命令有与w命令类似的用途,但它的功能比w命令更强大一些。语法格式如下:
who [OPTION]... [FILE | ARG1 ARG2]who常用命令如下:
# 显示当前登录的所有用户信息
who
# 显示系统的启动时间
who -b
# 显示系统登录进程
who -l
# 显示与当前标准输入关联的用户信息
who -m
# 显示系统的运行级别
who -r
# 显示所有登录用户的用户名和登录用户数
who -q4. uname - 查看系统信息
uname命令用于打印内核名称和版本、主机名等系统信息。命令的语法如下所示:
uname [OPTION]...常用使用方式如下:
# 只打印内核的名称
uname
# 使用 -n 选项,只打印系统的主机名
uname -n
# 使用 -r 选项,打印内核版本信息
uname -r
# 使用 -m 选项,打印系统的硬件名称
uname -m
# 使用 -p 选项,打印系统的处理器类型信息
uname -p
# 使用 -i 选项,打印系统的硬件平台信息
uname -i
# 使用 -a 选项,打印上述所有示例中的信息
uname -a5. date - 显示和设置系统日期和时间
date命令用于以多种格式显示日期和时间,或设置系统的日期和时间。date命令的语法如下所示:
date [OPTION]... [+FORMAT]
date [-u|--utc|--universal] [MMDDhhmm[[CC]YY][.ss]]常用使用命令如下:
# 以默认格式显示系统的当前日期时间
date
# 格式化当前日期
date +"%Y-%m-%d"
# 格式化输出昨天的日期
date -d "1 day ago" +"%Y-%m-%d"
# 2秒后格式化输出
date -d "2 second" +"%Y-%m-%d %H:%M.%S"
# 普通格式化转出
date -d "2009-12-12" +"%Y/%m/%d %H:%M.%S"
# apache格式转换
date -d "Dec 5, 2009 12:00:37 AM" +"%Y-%m-%d %H:%M.%S"
# 日期加减操作
date +%Y%m%d #显示前天年月日
date -d "+1 day" +%Y%m%d #显示前一天的日期
date -d "-1 day" +%Y%m%d #显示后一天的日期
date -d "-1 month" +%Y%m%d #显示上一月的日期
date -d "+1 month" +%Y%m%d #显示下一月的日期
date -d "-1 year" +%Y%m%d #显示前一年的日期
date -d "+1 year" +%Y%m%d #显示下一年的日期
# 设定时间
date -s # 设置当前时间,只有root权限才能设置,其他只能查看
date -s 20160816 # 设置成20160816,这样会把具体时间设置成空00:00:00
date -s 01:01:01 # 设置具体时间,不会对日期做更改
date -s "01:01:01 2012-05-23" # 这样可以设置全部时间
date -s "01:01:01 20120523" # 这样可以设置全部时间
date -s "2012-05-23 01:01:01" # 这样可以设置全部时间
date -s "20120523 01:01:01" # 这样可以设置全部时间6. id - 显示用户属性
id命令用于打印输出用户uid、gid、用户名和组名等用户身份信息。id命令的语法如下所示:
id [OPTION]... [USERNAME]常见使用命令如下:
# 输出当前用户的uid、用户名、gid、组名及用户属于的群组信息
id
# 使用 -u 选项,输出用户的 uid
id -u
#-u 选项和 -n 选项结合使用,输出账户的用户名
id -un
# 使用 -g 选项,输出帐号当前起作用的gid
id -g
# -g 与 -n 选项结合使用,输出帐号当前起作用的用户组名
id -gn
# 使用 -G 选项,输出帐号所属的所有群组id
id -G root
# -G 与 -n 选项结合使用,输出账号所属的所有群组的名称
id -Gn root文件和目录操作
1. touch - 创建文件
touch命令就可用于创建、变更和修改文件的时间戳。它是 Linux 操作系统的标准程序。touch命令又如下选项:
-a: 只改变访问时间
-c: 不创建任何文件
-m: 只改变修改时间
-r: 使用指定文件的时间替代当前时间
-t: 使用 [[CC]YY]MMDDhhmm[.ss] 替代当前时间touch 命令的常见用法如下:
# 创建一个名为 effyl 的新空文件
touch effyl
# 同时创建名称分别为 effyl myeffyl lueffyl 的三个文件
touch effyl myeffyl lueffyl
# 使用 -a 选项,可以改变或更新文件的最新访问时间,如果文件 effyl 不存在,则新创建一个
touch -a effyl
# 使用 -c 选项,可以避免创建一个新文件,并用当前时间更新文件的时间戳
touch -c effyl
# 使用 -m 选项,可以只改变文件的修改时间,而访问时间不变
touch -m effyl
# 使用 -c 和 -t 选项,来明确设置文件的时间
touch -c -t YYMMDDHHMM filename
# 如果想使用文件 myeffyl 的时间戳更新文件 effyl 的时间戳,可以使用 -r 选项
touch -r myeffyl effyl2.mkdir - 创建目录
mkdir命令用于创建一个新目录。最基本的mkdir命令的使用方法如下所示:
# 在当前目录下创建一个给定的目录名
mkdir <dirname>
# 在 backup 中的相对路径创建一个名为 old 的目录
mkdir backup/old
# 在 backup 中的绝对路径中创建一个名为 old 的目录
mkdir /home/blinkfox/backup/old
# 使用 -p 选项,会自动创建所有还不存在的父目录
mkdir -p backup/old
# 使用 -m 选项,可以设置将要创建目录的权限
# 如:创建一个任何人都有读写访问权限的目录
mkdir -p -m 777 backup/old3.cp - 复制文件或目录
cp命令用于将文件从一个地方复制到另一个地方。原来的文件保持不变,新文件可能保持原名或用一个不同的名字。
使用 cp 命令复制文件和目录的语法有以下几种:
# 复制源文件到目标文件
cp [OPTION] SOURCE DEST
# 复制一个或多个源文件到一个目录
cp [OPTION] SOURCE... DIRECTORY
# 同上
cp [OPTION] -t DIRECTORY SOURCE...常用使用示例如下:
# 在当前目录下,创建一个文件 file.txt 的副本,取名为 newfile.txt
cp file.txt newfile.txt
# 复制当前目录下的 file.txt 文件到 /tmp 目录下
cp file.txt /tmp
# 复制当前目录下的所有文件到 /tmp 目录下
cp * /tmp
# 使用 -p 选项,可以使复制一个文件到新文件时,保留源文件的所有者、权限等信息
cp -p filename /path/to/new/location/myfile
# 使用 -R 或 -r 选项,恶意递归地复制一个目录
# 即将一个目录及其下的所有文件和子目录都复制到另一个目录
cp -R * /home/blinkfox/backup4.ln - 链接文件或目录
ln命令用于创建软链接或硬链接。使用 -s 选项,可以创建一个软链接:
# 在目录 lib 下创建一个软链接 library.so,链接到 /home/blinkfox/src/library.so
ln -s /home/blinkfox/src/library.so /home/blinkfox/lib
# 创建目录的软链接
ln -s /home/blinkfox/src source5. mv - 移动文件或目录
mv命令用于将文件和目录从一个位置移到另外一个位置。除了移动文件,mv命令还可用于修改文件或目录的名字。
mv 命令的基本语法如下所示:
mv SOURCE... DIRECTORY常用命令如下:
# 将当前目录下的文件 source.txt 移到目录 /tmp 下
mv source.txt /tmp
# 将目录 dir1、dir2 移到目录 dir_dist 下
mv dir1 dir2 dir_dist
# 将当前目录下的 old.txt 文件更名为 new.txt
mv old.txt new.txt
# 使用 -i 选项,在重写覆盖目标文件或目录之前给出提示信息
mv -i old.txt new.txt
# 将当前目录下的所有文件移动到目录 /tmp 下
mv * /tmp/
# 使用 -i 选项,从 dir1 中移动那些在目标目录中不存在的文件到目标目录
mv -u dir1/* dir2/6.rm - 删除文件或目录
rm命令用于删除指定的文件和目录。其语法如下所示:
rm [OPTIONS]... FILE...rm的常用命令如下:
# 删除当前目录下的文件 file1.txt、file2.txt、file3.txt
rm file1.txt file2.txt file3.txt
# 删除当前目录下的所有文件
rm *
# 删除你当前帐号主目录下的 temp 目录中的所有文件
rm ~/temp/*
# 使用 -i 选项,可以在删除每个文件或目录前提示用户确认
rm -i *
# 删除当前目录下所有以".doc"结尾的文件
rm *.doc
# 删除当前目录下所有文件名中包含"movie"字符串的文件
rm *movie*
# 删除当前目录下所有以"a"开头的文件
rm a*
# 删除当前目录下整个文件名(包括扩展名)只有 3 个字符的所有文件
rm ???
# 删除当前目录下文件扩展名有两个字符的所有文件
rm *.??
# 删除当前目录下文件名中含有字母 a 或 b 或 c 的所有文件
rm *[abc]*
# 删除当前目录下文件名中包含 0~9 的所有文件
rm *[0-9]*
# 删除当前目录下文件扩展名是字母 c 或 h 的所有文件
rm *.[ch]
# 删除 /tmp 目录下的所有文件及其子目录
rm -rf /tmp/*-f 删除前不提示用户确认,并忽略不存在的文件 -r 递归地删除目录及其下的内容
7. ls - 列出文件名和目录
ls命令是Linux中最常用的命令之一,其作用就是列出文件名和目录。在命令行提示符下,直接输入ls命令,不带任何选项,将列出当前目录下所有文件和目录,但不会显示详细的信息,比如,文件类型、大小、修改日期和时间、权限等。
以下便是ls命令及其选项的作用说明:
# 仅列出当前目录下所有文件和目录
ls
# 每行显示一条记录,每条记录包括文件类型、大小、修改日期和时间、权限等
ls -l
# 将文件大小显示符合人类阅读习惯的格式
ls -lh
# 将使用不同的特殊字符归类不同的文件类型
ls -F
# 以长列表格式列出某个目录的信息
ls -ld /var/log
# 将递归地列出子目录的内容
ls -R /etc/sysconfig/
# 以长列表格式按文件或目录的修改时间倒序地列出文件和目录
ls -ltr
# 以长列表格式按文件大小顺序列出文件和目录
ls -ls
# 列出包括隐藏文件或目录在内的所有文件和目录,包括“.”(当前目录)和“..”(父目录)
ls -a
# 列出包括隐藏文件或目录在内的所有文件和目录,不包括“.”(当前目录)和“..”(父目录)
ls -A
输出的内容类似于-l选项,指示显示uid和gid,替代显示所有者和用户组
ls -n8. cat - 连接显示文件内容
cat 命令也是 Linux 系统中最常用的命令之一。cat命令让我们可以看看文件的内容、连接文件、创建一个或多个文件和重定向输出到终端或文件。
cat命令的语法如下所示:
cat [OPTION] [FILE]...cat常用命令如下:
# 使用 cat 命令查看文件 /etc/group 的内容
cat /etc/group
# 显示多个文件的内容
cat /etc/redhat-release /etc/issue
# -n 选项,可以显示文件内容的行号
cat -n /etc/fstab
# -b 选项和 -n 选项类似,但只标识非空白行的行号
cat -b /etc/fstab
# -e 选项,将在每一行的结尾显示“$”字符
cat -e /etc/fstab当你只输入 cat 命令,而没有任何参数时,它只是接收标准输入的内容并在标准输出中显示。所以你在输入一行内容并回车后,会在接下来的一行显示相同的内容。你也可以重定向标准输出到一个新文件。
9.less、more - 分屏显示文件
more命令在你使用小的 xterm 窗口时,或是想不使用文本编辑器而只是简单地阅读一个文件时是很有用的。more 命令是一个用于一次翻阅一整屏文件的过滤器。
# 查看一个文件,自动清空屏幕并显示文件开头部分
more /etc/inittab
# 指定一次显示num行
more -num /etc/inittab与more命令相比,我个人更喜欢less命令来查看文件。less命令与more命令类似,但less命令向前和向后翻页都支持,而且less命令不需要在查看前加载整个文件,即less命令查看文件更快速。
less常用命令参数如下:
-b <缓冲区大小> 设置缓冲区的大小
-e 当文件显示结束后,自动离开
-f 强迫打开特殊文件,例如外围设备代号、目录和二进制文件
-g 只标志最后搜索的关键词
-i 忽略搜索时的大小写
-m 显示类似more命令的百分比
-N 显示每行的行号
-o <文件名> 将less 输出的内容在指定文件中保存起来
-Q 不使用警告音
-s 显示连续空行为一行
-S 行过长时间将超出部分舍弃
-x <数字> 将“tab”键显示为规定的数字空格
/字符串:向下搜索“字符串”的功能
?字符串:向上搜索“字符串”的功能
n: 重复前一个搜索(与 / 或 ? 有关)
N: 反向重复前一个搜索(与 / 或 ? 有关)
b 向后翻一页
d 向后翻半页
h 显示帮助界面
Q 退出less 命令
u 向前滚动半页
y 向前滚动一行
空格键 滚动一行
回车键 滚动一页
[pagedown]: 向下翻动一页
[pageup]: 向上翻动一页10.head - 显示文件头部
head命令用于打印指定输入的开头部分内容。默认情况下,打印每个指定输入的前 10 行内容。
使用-n选项可以指定打印文件的前 N 行:
# 指定打印文件的前5行
head -n 5 /etc/inittab
(或)head -5 /etc/inittab
# 打印文件的前N个字节的数据
head -c 10 /etc/inittab11.tail - 显示文件尾部
tail命令和head命令相反,它打印指定输入的结尾部分的内容。默认情况下,它打印指定输入的最后 10 行内容。
使用-n选项可以指定打印文件的最后 N 行:
# 指定打印文件的后10行
tail -n 10 /etc/inittab
tail -10 /etc/inittab
# 即时打印文件中新写入的行
tail -f /var/log/messages
# --retry选项表示持续尝试打开某个文件,当你想打开一个稍后才会创建或即使不可用的文件
tail -f /tmp/debug.log --retry12.file - 查看文件类型
file命令用于接收一个文件作为参数并执行某些测试,已确定正确的文件类型。
# 查看文件类型
file /etc/inittab
# 可以MIME类型的格式显示文件类型的信息
file -i /etc/inittab
# 使用-N 选项,输出的队列可以以在文件名之后无空白填充的形式显示
file -N *13.wc - 查看文件统计信息
wc命令用于查看文件的行数、单词数和字符数等信息。语法类似如下所示:
wc filename
X Y Z /etc/inittab其中 X 表示行数,Y 表示单词数,Z 表示字节数,filename 表示文件名。
# -l选项,可以只统计文件的行数信息
wc -l /etc/inittab
# -w选项,可以只统计文件的单词数信息
wc -w /etc/inittab
# -c选项,可以只统计文件的字节数信息
wc -c /etc/inittab
# -L选项,可以只统计文件中最长的行的长度
wc -L /etc/inittab14.find - 查找文件或目录
find命令用于根据你指定的参数搜索和定位文件和目录的列表。find命令可以在多种情况下使用,比如你可以通过权限、用户、用户组、文件类型、日期、大小和其他可能的条件来查找文件。
find命令常用使用和说明如下:
# 查找指定目录下的某个文件
find /etc/ -name inittab
# 在当前目录下查找名称为 inittab 的文件
find . -name inittab
# 在当前目录下,文件不区分大小写是example的所有文件
find . -iname example
# 找出当前目录下所有以 sh 结尾的文件
find . -type f -name "*.sh"
# 找出当前目录下,文件权限是 777 的所有文件
find . -type f -perm 777
# 找出当前目录下,文件权限不是 777 的所有文件
find . -type f ! -perm 777
# 找出当前目录下所有只读文件
find . -type f ! -perm /a+w
# 找出你帐号主目录下的所有可执行文件
find ~ -type f -perm /a+w
# 找出 /tmp 目录下的.log文件并将其删除:
find /tmp/ -type f -name "*.log" -exec rm -f {} \;
# 找出当前目录下的所有空文件
find . -type f -empty
# 找出当前目录下的所有空目录
find . -type d -empty
# 找出 /tmp 目录下的所有隐藏文件
find /tmp/ -type f -name ".*"
# 找出 /tmp 目录下,所有者是 root 的文件和目录
find /tmp/ -user root
# 找出 /tmp 目录下,用户组是 developer 的文件和目录
find /tmp/ -group root
# 找出你账号的主目录下,3 天前修改的文件
find ~ -type f -mtime 3
# 找出你账号的主目录下,30 天以前修改的所有文件
find ~ -type f -mtime +30
# 找出你账号的主目录下,3 天以内修改的所有文件
find ~ -type f -mtime -3
# 找出你账号的主目录下,30 天以前,60 天以内修改的所有文件
find ~ -type f -mtime +30 -mtime -60
# 找出 /etc 目录下,一小时以内变更过的文件
find /etc -type f -cmin -60
# 找出 /etc 目录下,一小时以内访问过的文件
find /etc -type f -amin -60
# 找出你账号主目录下,大小是50MB的所有文件
find ~ -type f -size 50MB
# 找出你账号主目录下,大于50MB小于100MB的所有文件
find ~ -type f -size +50MB -size -100MB
# 找出你账号主目录下,大于100MB的文件并将其删除
find ~ -type f -size +100MB -exec rm -rf {} \;文本处理
1. sort - 文本排序
sort命令用于将文本文件的行排序。默认情况下,sort命令是按照字符串的字母顺序排序。
sort 的常用命令如下:
# 将文本内容按字母顺序排序
sort example.txt
# 使用 -u 选项,移除所有重复行后排序
sort -u example.txt
# 使用 -n 选项,将令数字按数值的大小排序
sort -n example.txt
# 使用 -r 选项,以倒序方式排序
sort -n -r example.txt
# 同时将 file1、file2 的内容排序
sort file1 file22.uniq - 文本去重
uniq命令用于移除或发现文件中重复的条目。
# 它将移除文件中重复的行并显示单一行
uniq example.txt
# 可以统计重复行出现的次数
uniq -c example.txt
# 使用 -d 选项,只显示文件中有重复的行并只显示一次
uniq -d example.txt
# 使用 -D 选项,显示文件中所有重复的行
uniq -D example.txt
# 使用 -u 选项,只显示文件中不重复的行
uniq -u example.txt
# 使用 -w 选项,限制 uniq 命令只比较每行的前 3 个字符是否重复
uniq -w 3 example.txt
# 使用 -s 选项,避免 uniq 命令比较每行的前 3 个字符,只比较后面的字符是否重复
uniq -s 3 example.txt
# 使用 -f 选项,避免 uniq 命令比较第一列的内容,只比较后面的字符是否重复
uniq -f 1 example.txt3.tr - 替换或删除字符
tr命令主要用于删除文件中控制字符或进行字符转换。使用tr时要转换两个字符串:字符串 1 用于查询,字符串 2 用于处理各种转换。tr刚执行时,字符串 1 中的字符被映射到字符串 2 中的字符,然后转换操作开始。
tr命令的语法如下所示:
tr [OPTION]... SET1 [SET2]常用命令示例:
# 若要将大括号转换为小括号
tr '{}' '()' < textfile > newfile
# 若要将大括号转换成方括号
tr '{}' '\[]' < textfile > newfile
# 若要将小写字符转换成大写,请输入:
tr 'a-z' 'A-Z' < textfile > newfile
# 若要创建一个文件中的单词列表
tr -cs '[:lower:][:upper:]' '[\n*]' < textfile > newfile
# 若要从某个文件中删除所有空字符
tr -d '\0' < textfile > newfile
# 若要用单独的换行替换每一序列的一个或多个换行,请输入:
tr -s '\n' < textfile > newfile
# 要以单个“#”字符替换 <space> 字符类中的每个字符序列
tr -s '[:space:]' '[#*]'4.grep - 查找字符串
grep命令用于搜索文本或指定的文件中与指定的字符串或模式相匹配的行。默认情况下,grep命令只显示匹配的行。
grep命令的语法如下所示:
grep [OPTION]... PATTERN [FILE]...
grep [OPTION]... [-e PATTERN | -f FILE] [FILE]...# `grep`命令查找文件/etc/passwd 中帐号 blinkfox 的信息
grep blinkfox /etc/passwd
# 使用 -i 选项,强制 grep 命令忽略搜索关键字的大小写
grep -i blinkfox /etc/passwd
# 使用 -r 选项,可以递归搜索指定目录下的所有文件
grep -r blinkfox /etc/
# 使用 -w 选项,只匹配包含指定单词的行
grep -w blinkfox /etc/
# 使用 -c 选项,报告文件或文本中模式被匹配的次数
grep -c blinkfox /etc/passwd
# 使用 -n 选项,显示每一个匹配的行的行号
grep -n blinkfox /etc/passwd
# 使用 -v 选项,可以输出除匹配指定模式的行以外的其他所有行
grep -v blinkfox /etc/passwd
# 使用 --color 选项,在输出中将匹配的字符串以彩色的形式标出
grep --color blinkfox /etc/passwd5.diff - 比较两个文件
diff命令用于比较两个文件,并找出它们之间的不同。diff命令的语法如下所示:
diff [OPTION]... from-file to-file常用使用方式如下:
# 比较两个文件
diff nsswitch.conf nsswitch.conf.org
# 使用 -w 选项,比较时忽略空格
diff -w nsswitch.conf nsswitch.conf.org
# 使用 -y 选项,以并排的格式输出两个文件的比较结果
diff -y nsswitch.conf nsswitch.conf.org
使用 -c 选项,以上下对比的格式输出两个文件的比较结果
diff -c nsswitch.conf nsswitch.conf.org操作命令
1. grep
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来,表示全局正则表达式版本,它的使用权限是所有用户。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
1.命令格式:
grep [option] pattern file
2.命令功能:
用于过滤/搜索的特定字符。可使用正则表达式能多种命令配合使用,使用上十分灵活。
3.命令参数:
-a --text #不要忽略二进制的数据。
-A<显示行数> --after-context=<显示行数> #除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-b --byte-offset #在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-B<显示行数> --before-context=<显示行数> #除了显示符合样式的那一行之外,并显示该行之前的内容。
-c --count #计算符合样式的列数。
-C<显示行数> --context=<显示行数>或-<显示行数> #除了显示符合样式的那一行之外,并显示该行之前后的内容。
-d <动作> --directories=<动作> #当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式> --regexp=<范本样式> #指定字符串做为查找文件内容的样式。
-E --extended-regexp #将样式为延伸的普通表示法来使用。
-f<规则文件> --file=<规则文件> #指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-F --fixed-regexp #将样式视为固定字符串的列表。
-G --basic-regexp #将样式视为普通的表示法来使用。
-h --no-filename #在显示符合样式的那一行之前,不标示该行所属的文件名称。
-H --with-filename #在显示符合样式的那一行之前,表示该行所属的文件名称。
-i --ignore-case #忽略字符大小写的差别。
-l --file-with-matches #列出文件内容符合指定的样式的文件名称。
-L --files-without-match #列出文件内容不符合指定的样式的文件名称。
-n --line-number #在显示符合样式的那一行之前,标示出该行的列数编号。
-q --quiet或--silent #不显示任何信息。
-r --recursive #此参数的效果和指定“-d recurse”参数相同。
-s --no-messages #不显示错误信息。
-v --revert-match #显示不包含匹配文本的所有行。
-V --version #显示版本信息。
-w --word-regexp #只显示全字符合的行列。
-x --line-regexp #只显示全行符合的行。
-y #此参数的效果和指定“-i”参数相同。
- 示例说明
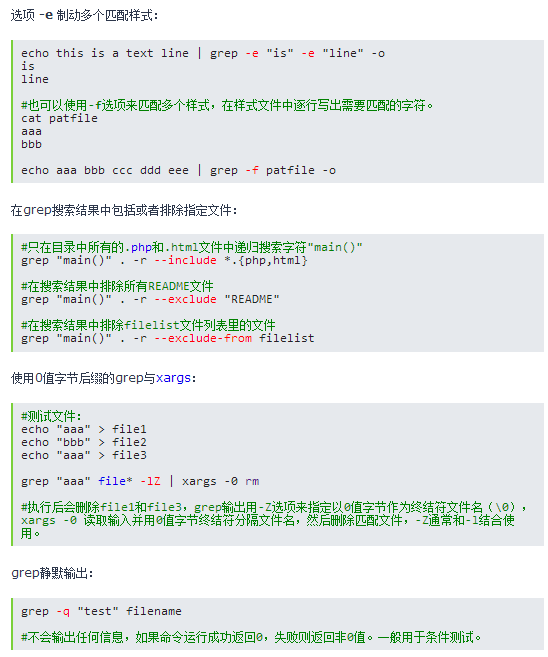
2. awk
使用示例
我从netstat命令中提取了如下信息作为用例:
$ cat netstat.txt
Proto Recv-Q Send-Q Local-Address Foreign-Address State
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:9000 0.0.0.0:* LISTEN
tcp 0 0 coolshell.cn:80 124.205.5.146:18245 TIME_WAIT
tcp 0 0 coolshell.cn:80 61.140.101.185:37538 FIN_WAIT2
tcp 0 0 coolshell.cn:80 110.194.134.189:1032 ESTABLISHED
tcp 0 0 coolshell.cn:80 123.169.124.111:49809 ESTABLISHED
tcp 0 0 coolshell.cn:80 116.234.127.77:11502 FIN_WAIT2
tcp 0 0 coolshell.cn:80 123.169.124.111:49829 ESTABLISHED
tcp 0 0 coolshell.cn:80 183.60.215.36:36970 TIME_WAIT
tcp 0 4166 coolshell.cn:80 61.148.242.38:30901 ESTABLISHED
tcp 0 1 coolshell.cn:80 124.152.181.209:26825 FIN_WAIT1
tcp 0 0 coolshell.cn:80 110.194.134.189:4796 ESTABLISHED
tcp 0 0 coolshell.cn:80 183.60.212.163:51082 TIME_WAIT
tcp 0 1 coolshell.cn:80 208.115.113.92:50601 LAST_ACK
tcp 0 0 coolshell.cn:80 123.169.124.111:49840 ESTABLISHED
tcp 0 0 coolshell.cn:80 117.136.20.85:50025 FIN_WAIT2
tcp 0 0 :::22 :::* LISTEN下面是最简单最常用的awk示例,其输出第1列和第4例,
- 其中单引号中的被大括号括着的就是awk的语句,注意,其只能被单引号包含。
- 其中的$1..$n表示第几例。注:$0表示整个行。
$ awk '{print **$1**, **$4**}' netstat.txt
Proto Local-Address
tcp 0.0.0.0:3306
tcp 0.0.0.0:80
tcp 127.0.0.1:9000
tcp coolshell.cn:80
tcp coolshell.cn:80
tcp coolshell.cn:80
tcp coolshell.cn:80
tcp coolshell.cn:80
tcp coolshell.cn:80
tcp coolshell.cn:80
tcp coolshell.cn:80
tcp coolshell.cn:80
tcp coolshell.cn:80
tcp coolshell.cn:80
tcp coolshell.cn:80
tcp coolshell.cn:80
tcp coolshell.cn:80
tcp :::22
#### 基本用法
`awk`的基本用法就是下面的形式。
> ```bash
> # 格式
> $ awk 动作 文件名
>
> # 示例
> $ awk '{print $0}' demo.txt
> ```
上面示例中,`demo.txt`是`awk`所要处理的文本文件。前面单引号内部有一个大括号,里面就是每一行的处理动作`print $0`。其中,`print`是打印命令,`$0`代表当前行,因此上面命令的执行结果,就是把每一行原样打印出来。
下面,我们先用标准输入(stdin)演示上面这个例子。
> ```bash
> $ echo 'this is a test' | awk '{print $0}'
> this is a test
> ```
上面代码中,`print $0`就是把标准输入`this is a test`,重新打印了一遍。
`awk`会根据空格和制表符,将每一行分成若干字段,依次用`$1`、`$2`、`$3`代表第一个字段、第二个字段、第三个字段等等。
> ```bash
> $ echo 'this is a test' | awk '{print $3}'
> a
> ```
上面代码中,`$3`代表`this is a test`的第三个字段`a`。
下面,为了便于举例,我们把`/etc/passwd`文件保存成`demo.txt`。
> ```bash
> root:x:0:0:root:/root:/usr/bin/zsh
> daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
> bin:x:2:2:bin:/bin:/usr/sbin/nologin
> sys:x:3:3:sys:/dev:/usr/sbin/nologin
> sync:x:4:65534:sync:/bin:/bin/sync
> ```
这个文件的字段分隔符是冒号(`:`),所以要用`-F`参数指定分隔符为冒号。然后,才能提取到它的第一个字段。
> ```bash
> $ awk -F ':' '{ print $1 }' demo.txt
> root
> daemon
> bin
> sys
> sync
> ```
#### 变量
除了`$ + 数字`表示某个字段,`awk`还提供其他一些变量。
变量`NF`表示当前行有多少个字段,因此`$NF`就代表最后一个字段。
> ```bash
> $ echo 'this is a test' | awk '{print $NF}'
> test
> ```
`$(NF-1)`代表倒数第二个字段。
> ```bash
> $ awk -F ':' '{print $1, $(NF-1)}' demo.txt
> root /root
> daemon /usr/sbin
> bin /bin
> sys /dev
> sync /bin
> ```
上面代码中,`print`命令里面的逗号,表示输出的时候,两个部分之间使用空格分隔。
变量`NR`表示当前处理的是第几行。
> ```bash
> $ awk -F ':' '{print NR ") " $1}' demo.txt
> 1) root
> 2) daemon
> 3) bin
> 4) sys
> 5) sync
> ```
上面代码中,`print`命令里面,如果原样输出字符,要放在双引号里面。
`awk`的其他内置变量如下。
> - `FILENAME`:当前文件名
> - `FS`:字段分隔符,默认是空格和制表符。
> - `RS`:行分隔符,用于分割每一行,默认是换行符。
> - `OFS`:输出字段的分隔符,用于打印时分隔字段,默认为空格。
> - `ORS`:输出记录的分隔符,用于打印时分隔记录,默认为换行符。
> - `OFMT`:数字输出的格式,默认为`%.6g`。
#### 函数
`awk`还提供了一些内置函数,方便对原始数据的处理。
函数`toupper()`用于将字符转为大写。
> ```bash
> $ awk -F ':' '{ print toupper($1) }' demo.txt
> ROOT
> DAEMON
> BIN
> SYS
> SYNC
> ```
上面代码中,第一个字段输出时都变成了大写。
其他常用函数如下。
> - `tolower()`:字符转为小写。
> - `length()`:返回字符串长度。
> - `substr()`:返回子字符串。
> - `sin()`:正弦。
> - `cos()`:余弦。
> - `sqrt()`:平方根。
> - `rand()`:随机数。
`awk`内置函数的完整列表,可以查看[手册](https://www.gnu.org/software/gawk/manual/html_node/Built_002din.html#Built_002din)。
#### 条件
`awk`允许指定输出条件,只输出符合条件的行。
输出条件要写在动作的前面。
> ```bash
> $ awk '条件 动作' 文件名
> ```
请看下面的例子。
> ```bash
> $ awk -F ':' '/usr/ {print $1}' demo.txt
> root
> daemon
> bin
> sys
> ```
上面代码中,`print`命令前面是一个正则表达式,只输出包含`usr`的行。
下面的例子只输出奇数行,以及输出第三行以后的行。
> ```bash
> # 输出奇数行
> $ awk -F ':' 'NR % 2 == 1 {print $1}' demo.txt
> root
> bin
> sync
>
> # 输出第三行以后的行
> $ awk -F ':' 'NR >3 {print $1}' demo.txt
> sys
> sync
> ```
下面的例子输出第一个字段等于指定值的行。
> ```bash
> $ awk -F ':' '$1 == "root" {print $1}' demo.txt
> root
>
> $ awk -F ':' '$1 == "root" || $1 == "bin" {print $1}' demo.txt
> root
> bin
> ```
#### if 语句
`awk`提供了`if`结构,用于编写复杂的条件。
> ```bash
> $ awk -F ':' '{if ($1 > "m") print $1}' demo.txt
> root
> sys
> sync
> ```
上面代码输出第一个字段的第一个字符大于`m`的行。
`if`结构还可以指定`else`部分。
> ```bash
> $ awk -F ':' '{if ($1 > "m") print $1; else print "---"}' demo.txt
> root
> ---
> ---
> sys
> sync
> ```
### 3. xargs&管道符
#### 标准输入与管道命令
Unix 命令都带有参数,有些命令可以接受"标准输入"(stdin)作为参数。
> ```bash
> $ cat /etc/passwd | grep root
> ```
上面的代码使用了管道命令(`|`)。管道命令的作用,是将左侧命令(`cat /etc/passwd`)的标准输出转换为标准输入,提供给右侧命令(`grep root`)作为参数。
因为`grep`命令可以接受标准输入作为参数,所以上面的代码等同于下面的代码。
> ```bash
> $ grep root /etc/passwd
> ```
但是,大多数命令都不接受标准输入作为参数,只能直接在命令行输入参数,这导致无法用管道命令传递参数。举例来说,`echo`命令就不接受管道传参。
> ```bash
> $ echo "hello world" | echo
> ```
上面的代码不会有输出。因为管道右侧的`echo`不接受管道传来的标准输入作为参数。
#### xargs 命令的作用
`xargs`命令的作用,是将标准输入转为命令行参数。
> ```bash
> $ echo "hello world" | xargs echo
> hello world
> ```
上面的代码将管道左侧的标准输入,转为命令行参数`hello world`,传给第二个`echo`命令。
`xargs`命令的格式如下。
> ```bash
> $ xargs [-options] [command]
> ```
真正执行的命令,紧跟在`xargs`后面,接受`xargs`传来的参数。
`xargs`的作用在于,大多数命令(比如`rm`、`mkdir`、`ls`)与管道一起使用时,都需要`xargs`将标准输入转为命令行参数。
> ```bash
> $ echo "one two three" | xargs mkdir
> ```
上面的代码等同于`mkdir one two three`。如果不加`xargs`就会报错,提示`mkdir`缺少操作参数。
#### xargs使用详解
xargs(英文全拼: eXtended ARGuments)是给命令传递参数的一个过滤器,也是组合多个命令的一个工具。
xargs 可以将管道或标准输入(stdin)数据转换成命令行参数,也能够从文件的输出中读取数据。
xargs 也可以将单行或多行文本输入转换为其他格式,例如多行变单行,单行变多行。
xargs 默认的命令是 echo,这意味着通过管道传递给 xargs 的输入将会包含换行和空白,不过通过 xargs 的处理,换行和空白将被空格取代。
xargs 是一个强有力的命令,它能够捕获一个命令的输出,然后传递给另外一个命令。
之所以能用到这个命令,关键是由于很多命令不支持|管道来传递参数,而日常工作中有有这个必要,所以就有了 xargs 命令,例如:
find /sbin -perm +700 |ls -l #这个命令是错误的 find /sbin -perm +700 |xargs ls -l #这样才是正确的
xargs 一般是和管道一起使用。
**命令格式:**
somecommand |xargs -item command
**参数:**
- -a file 从文件中读入作为 stdin
- -e flag ,注意有的时候可能会是-E,flag必须是一个以空格分隔的标志,当xargs分析到含有flag这个标志的时候就停止。
- -p 当每次执行一个argument的时候询问一次用户。
- -n num 后面加次数,表示命令在执行的时候一次用的argument的个数,默认是用所有的。
- -t 表示先打印命令,然后再执行。
- -i 或者是-I,这得看linux支持了,将xargs的每项名称,一般是一行一行赋值给 {},可以用 {} 代替。
- -r no-run-if-empty 当xargs的输入为空的时候则停止xargs,不用再去执行了。
- -s num 命令行的最大字符数,指的是 xargs 后面那个命令的最大命令行字符数。
- -L num 从标准输入一次读取 num 行送给 command 命令。
- -l 同 -L。
- -d delim 分隔符,默认的xargs分隔符是回车,argument的分隔符是空格,这里修改的是xargs的分隔符。
- -x exit的意思,主要是配合-s使用。。
- -P 修改最大的进程数,默认是1,为0时候为as many as it can ,这个例子我没有想到,应该平时都用不到的吧。
#### 实例
xargs 用作替换工具,读取输入数据重新格式化后输出。
定义一个测试文件,内有多行文本数据:
cat test.txt
a b c d e f g h i j k l m n o p q r s t u v w x y z
多行输入单行输出:
cat test.txt | xargs
a b c d e f g h i j k l m n o p q r s t u v w x y z
-n 选项多行输出:
cat test.txt | xargs -n3
a b c d e f g h i j k l m n o p q r s t u v w x y z
-d 选项可以自定义一个定界符:
echo "nameXnameXnameXname" | xargs -dX
name name name name
结合 -n 选项使用:
echo "nameXnameXnameXname" | xargs -dX -n2
name name name name
读取 stdin,将格式化后的参数传递给命令
假设一个命令为 sk.sh 和一个保存参数的文件 arg.txt:
!/bin/bash
sk.sh命令内容,打印出所有参数。
echo $*
arg.txt文件内容:
cat arg.txt
aaa bbb ccc
xargs 的一个选项 -I,使用 -I 指定一个替换字符串 {},这个字符串在 xargs 扩展时会被替换掉,当 -I 与 xargs 结合使用,每一个参数命令都会被执行一次:
cat arg.txt | xargs -I {} ./sk.sh -p {} -l
-p aaa -l -p bbb -l -p ccc -l
复制所有图片文件到 /data/images 目录下:
ls *.jpg | xargs -n1 -I {} cp {} /data/images
xargs 结合 find 使用
用 rm 删除太多的文件时候,可能得到一个错误信息:**/bin/rm Argument list too long.** 用 xargs 去避免这个问题:
find . -type f -name "*.log" -print0 | xargs -0 rm -f
xargs -0 将 \0 作为定界符。
统计一个源代码目录中所有 php 文件的行数:
find . -type f -name "*.php" -print0 | xargs -0 wc -l
查找所有的 jpg 文件,并且压缩它们:
find . -type f -name "*.jpg" -print | xargs tar -czvf images.tar.gz
xargs 其他应用
假如你有一个文件包含了很多你希望下载的 URL,你能够使用 xargs下载所有链接:
cat url-list.txt | xargs wget -c