Flink架构以及核心原理
为了支持分布式运行,Flink跟其他大数据引擎一样,采用了主从(Master-Worker)架构。Flink运行时主要包括两个组件:
• Master是一个Flink作业的主进程。它起到了协调管理的作用。
• TaskManager,又被称为Worker或Slave,是执行计算任务的进程。它拥有CPU、内存等计算资源。Flink作业需要将计算任务分发到多个TaskManager上并行执行。
下面将从作业执行层面来分析Flink各个模块如何工作。
Flink作业提交过程
Flink为适应不同的基础环境(Standalone集群、YARN、Kubernetes),在不断的迭代开发过程中已经逐渐形成了一个兼容性很强的架构。不同的基础环境对计算资源的管理方式略有不同,不过都大同小异,下图以Standalone集群为例,分析作业的分布式执行流程。Standalone模式指Flink独占该集群,集群上无其他任务。
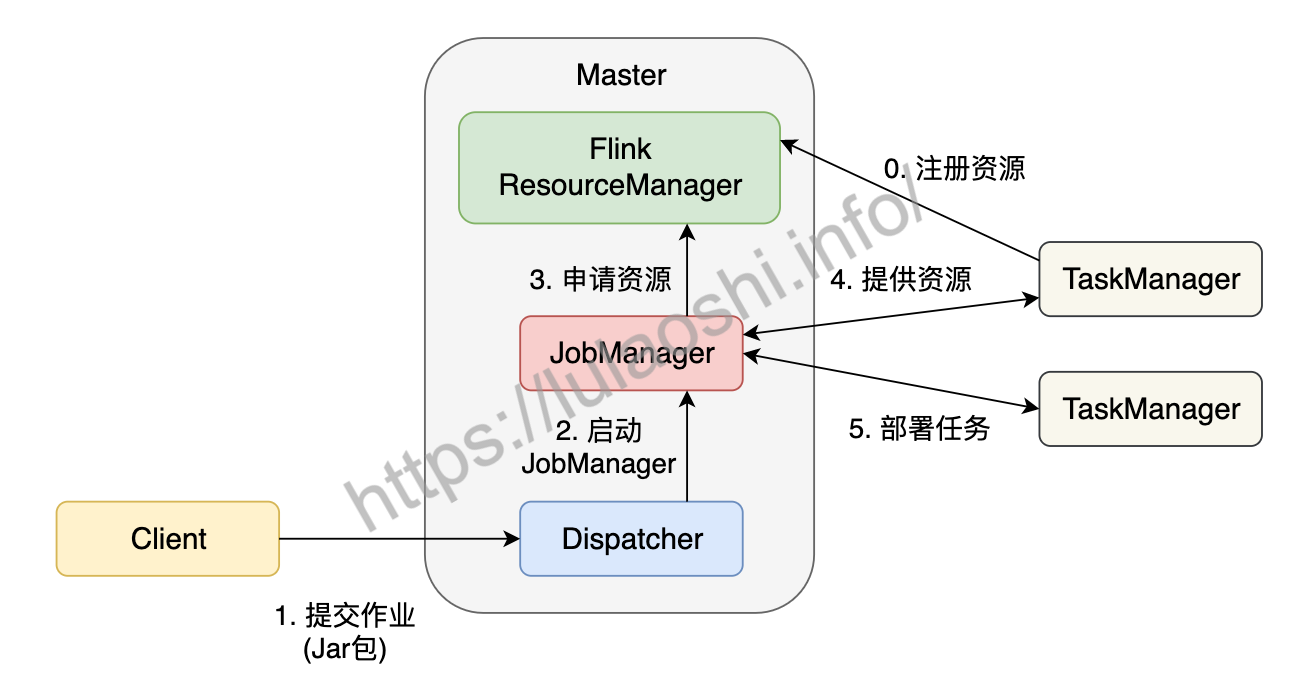
在一个作业提交前,Master和TaskManager等进程需要先被启动。我们可以在Flink主目录中执行脚本来启动这些进程:bin/start-cluster.sh。Master和TaskManager被启动后,TaskManager需要将自己注册给Master中的ResourceManager。这个初始化和资源注册过程发生在单个作业提交前,我们称之为第0步。
接下来我们根据上图,逐步分析一个Flink作业如何被提交:
- 用户编写应用程序代码,并通过Flink客户端(Client)提交作业。程序一般为Java或Scala语言,调用Flink API,构建逻辑视角数据流图。代码和相关配置文件被编译打包,被提交到Master的Dispatcher,形成一个应用作业(Application)。
- Dispatcher接收到这个作业,启动JobManager,这个JobManager会负责本次作业的各项协调工作。
- JobManager向ResourceManager申请本次作业所需资源。
- 由于在第0步中TaskManager已经向ResourceManager中注册了资源,这时闲置的TaskManager会被反馈给JobManager。
- JobManager将用户作业中的逻辑视图转化为图所示的并行化的物理执行图,将计算任务分发部署到多个TaskManager上。至此,一个Flink作业就开始执行了。
TaskManager在执行计算任务过程中可能会与其他TaskManager交换数据,会使用图中的一些数据交换策略。同时,TaskManager也会将一些任务状态信息会反馈给JobManager,这些信息包括任务启动、运行或终止的状态,快照的元数据等。
Flink核心组件
有了这个作业提交流程,我们对各组件的功能应该有了更全面的认识,接下来我们再对涉及到的各个组件进行更为详细的介绍。
Client
用户一般使用客户端(Client)提交作业,比如Flink主目录下的bin目录中提供的命令行工具。Client会对用户提交的Flink程序进行预处理,并把作业提交到Flink集群上。Client提交作业时需要配置一些必要的参数,比如使用Standalone集群还是YARN集群等。整个作业被打成了Jar包,DataStream API被转换成了JobGraph,JobGraph是一种类似逻辑视图。
Dispatcher
Dispatcher可以接收多个作业,每接收一个作业,Dispatcher都会为这个作业分配一个JobManager。Dispatcher对外提供一个REST式的接口,以HTTP的形式来对外提供服务。
JobManager
JobManager是单个Flink作业的协调者,一个作业会有一个JobManager来负责。JobManager会将Client提交的JobGraph转化为ExceutionGraph,ExecutionGraph是类似并行的物理执行图。JobManager会向ResourceManager申请必要的资源,当获取足够的资源后,JobManager将ExecutionGraph以及具体的计算任务分发部署到多个TaskManager上。同时,JobManager还负责管理多个TaskManager,这包括:收集作业的状态信息,生成检查点,必要时进行故障恢复等问题。 早期,Flink Master被命名为JobManager,负责绝大多数Master进程的工作。随着迭代和开发,出现了名为JobMaster的组件,JobMaster负责单个作业的执行。本书中,我们仍然使用JobManager的概念,表示负责单个作业的组件。一些Flink文档也可能使用JobMaster的概念,读者可以将JobMaster等同于JobManager看待。
ResourceManager
如前文所说,Flink现在可以部署在Standalone、YARN或Kubernetes等环境上,不同环境中对计算资源的管理模式略有不同,Flink使用一个名为ResourceManager的模块来统一处理资源分配上的问题。在Flink中,计算资源的基本单位是TaskManager上的任务槽位(Task Slot,简称槽位Slot)。ResourceManager的职责主要是从YARN等资源提供方获取计算资源,当JobManager有计算需求时,将空闲的Slot分配给JobManager。当计算任务结束时,ResourceManager还会重新收回这些Slot。
TaskManager
TaskManager是实际负责执行计算的节点。一般地,一个Flink作业是分布在多个TaskManager上执行的,单个TaskManager上提供一定量的Slot。一个TaskManager启动后,相关Slot信息会被注册到ResourceManager中。当某个Flink作业提交后,ResourceManager会将空闲的Slot提供给JobManager。JobManager获取到空闲Slot信息后会将具体的计算任务部署到该Slot之上,任务开始在这些Slot上执行。在执行过程,由于要进行数据交换,TaskManager还要和其他TaskManager进行必要的数据通信。
总之,TaskManager负责具体计算任务的执行,启动时它会将Slot资源向ResourceManager注册。
Flink组件栈
了解Flink的主从架构、作业提交以及核心组件等知识后,我们再从更宏观的角度来对Flink的组件栈分层剖析。如下图所示,Flink的组件栈分为四层:部署层、运行时层、API层和上层工具。
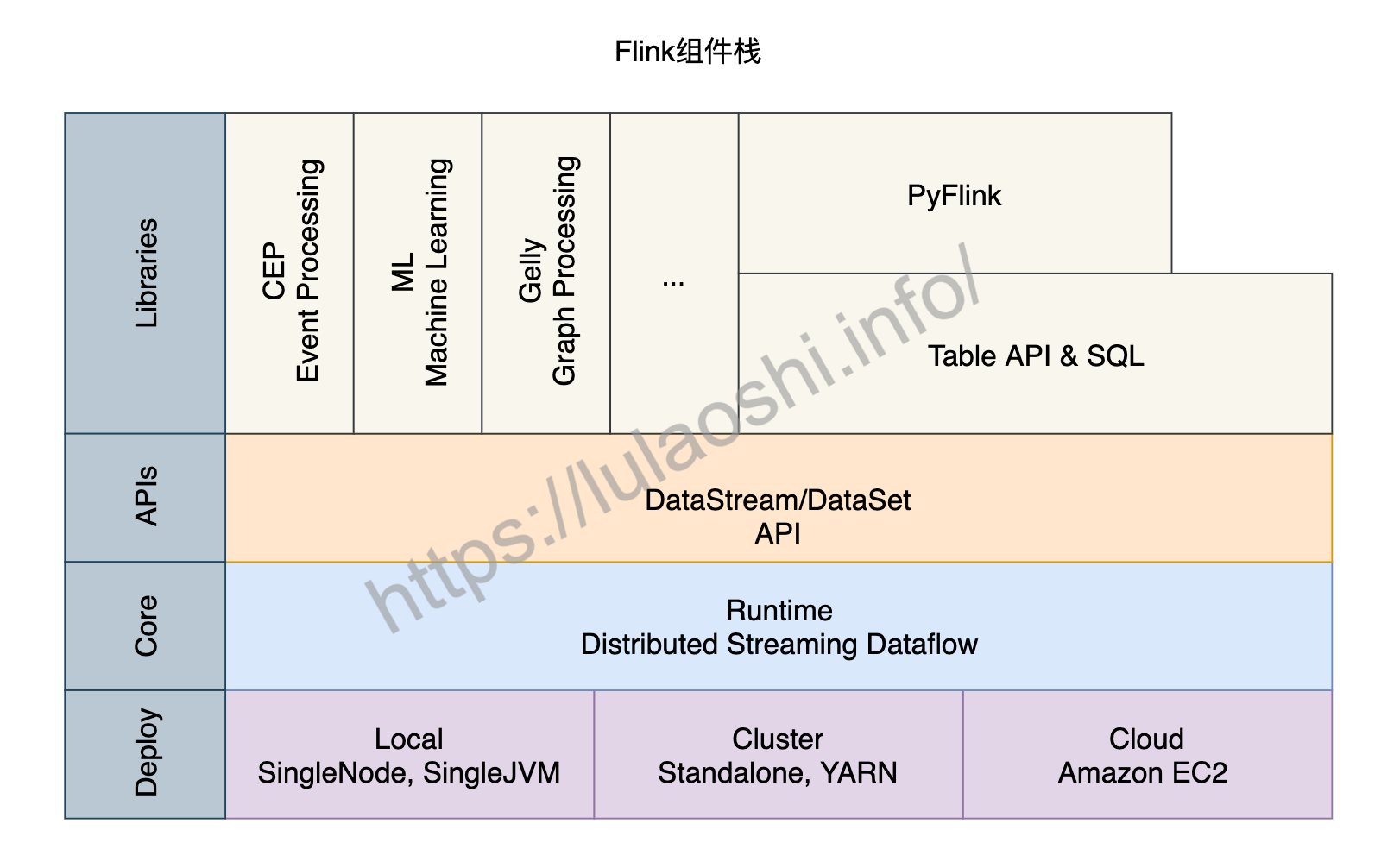
部署层
Flink支持多种部署方式,可以部署在单机(Local)、集群(Cluster),以及云(Cloud)上。
- Local模式
Local模式有两种不同的方式,一种是单节点(SingleNode),一种是单虚拟机(SingleJVM)。
Local-SingleJVM模式大多是开发和测试时使用的部署方式,该模式下JobManager和TaskManager都在同一个JVM里。
Local-SingleNode模式下,JobManager和TaskManager等所有角色都运行在一台机器上,虽然是按照分布式集群架构进行部署,但是集群的节点只有1个。该模式大多是在测试或者IoT设备上进行部署时使用。
- Cluster模式
Flink作业投入到生产环境下一般使用Cluster模式,可以是Standalone的独立集群,也可以是YARN或Kubernetes集群。
对于一个Standalone集群,我们需要在配置文件中配置好JobManager和TaskManager对应的机器,然后使用Flink主目录下的脚本启动一个Standalone集群。我们将在9.1.1详细介绍如何部署一个Flink Standalone集群。Standalone集群上只运行Flink作业。除了Flink,绝大多数企业的生产环境运行着包括MapReduce、Spark等各种各样的计算任务,一般都会使用YARN或Kubernetes等方式对计算资源进行管理和调度。Flink目前已经支持了YARN、Mesos以及Kubernetes,开发者提交作业的方式变得越来越简单。
- Cloud模式
Flink也可以部署在各大云平台上,包括Amazon、Google和阿里云。
运行时层
运行时(Runtime)层为Flink各类计算提供了实现。这一层读本章提到的分布式执行进行了支持。Flink Runtime层是Flink最底层也是最核心的组件。
API层
API层主要实现了流处理DataStream API和批处理DataSet API。目前,DataStream API针对有界和无界数据流,DataSet API针对有界数据集。用户可以使用这两大API进行数据处理,包括转换(Transformation)、连接(Join)、聚合(Aggregation)、窗口(Window)以及状态(State)的计算。
上层工具
在DataStream和DataSet两大API之上,Flink还提供了更丰富的工具,包括:
- 面向流处理的:复杂事件处理(Complex Event Process,CEP)。
- 面向批处理的:机器学习计算库(Machine Learning, ML)、图计算库(Graph Processing, Gelly)。
- 面向SQL用户的Table API和SQL。数据被转换成了关系型数据库式的表,每个表拥有一个表模式(Schema),用户可以像操作表那样操作流式数据,例如可以使用SELECT、JOIN、GROUP BY等操作。
- 针对Python用户推出的PyFlink,方便Python社区使用Flink。目前,PyFlink主要基于Java的Table API之上。
再谈逻辑视图到物理执行图
了解了Flink的分布式架构和核心组件,这里我们从更细粒度上来介绍从逻辑视图转化为物理执行图过程,该过程可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。我们根据下图来大致了解一些这些图的功能。
-
StreamGraph:根据用户编写的代码生成的最初的图,用来表示一个Flink流处理作业的拓扑结构。在StreamGraph中,节点StreamNode就是算子。 -
JobGraph:JobGraph是提交给 JobManager 的数据结构。StreamGraph经过优化后生成了JobGraph,主要的优化为,将多个符合条件的节点链接在一起作为一个JobVertex节点,这样可以减少数据交换所需要的传输开销。这个链接的过程叫做算子链(Operator Chain),我们会在下一小节继续介绍算子链。JobVertex经过算子链后,会包含一到多个算子,它的输出是IntermediateDataSet,这是经过算子处理产生的数据集。 -
ExecutionGraph:JobManager将JobGraph转化为ExecutionGraph。ExecutionGraph是JobGraph的并行化版本:假如某个JobVertex的并行度是2,那么它将被划分为2个ExecutionVertex,ExecutionVertex表示一个算子子任务,它监控着单个子任务的执行情况。每个ExecutionVertex会输出一个IntermediateResultPartition,这是单个子任务的输出,再经过ExecutionEdge输出到下游节点。ExecutionJobVertex是这些并行子任务的合集,它监控着整个算子的运行情况。ExecutionGraph是调度层非常核心的数据结构。 - 物理执行图:JobManager根据
ExecutionGraph对作业进行调度后,在各个TaskManager上部署具体的任务,物理执行图并不是一个具体的数据结构。
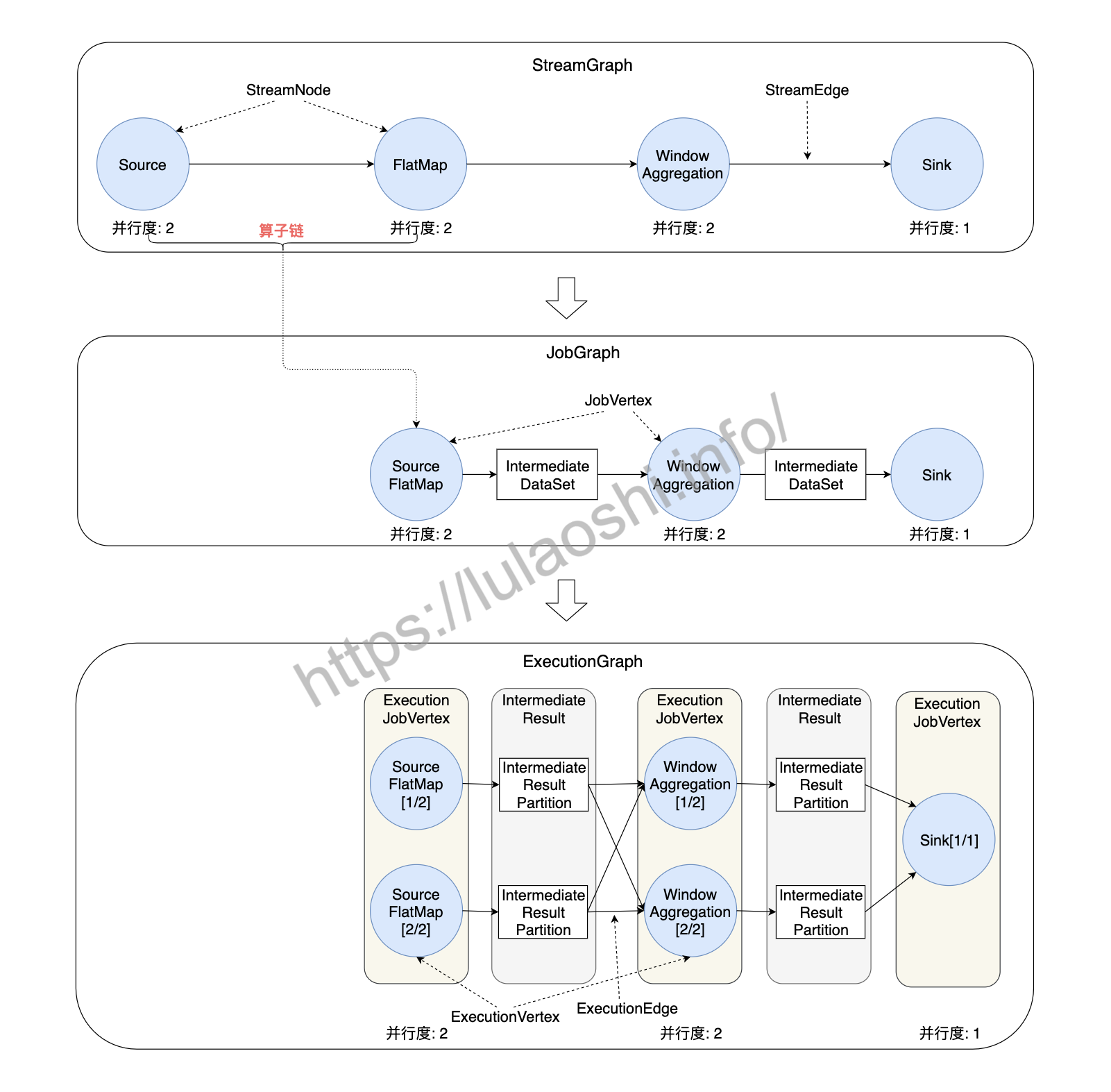
可以看到,Flink在数据流图上可谓煞费苦心,仅各类图就有四种之多。对于新人来说,可以不用太关心这些非常细节的底层实现,只需要了解以下几个核心概念:
-
Flink采用主从架构,Master起着管理协调作用,TaskManager负责物理执行,在执行过程中会发生一些数据交换、生命周期管理等事情。
- 用户调用Flink API,构造逻辑视图,Flink会对逻辑视图优化,并转化为并行化的物理执行图,最后被执行的是物理执行图。
任务、算子子任务与算子链
在构造物理执行图的过程中,Flink会将一些算子子任务链接在一起,组成算子链。链接后以任务(Task)的形式被TaskManager调度执行。使用算子链是一个非常有效的优化,它可以有效降低算子子任务之间的传输开销。链接之后形成的Task是TaskManager中的一个线程。下图展示了任务、子任务和算子链之间的关系。
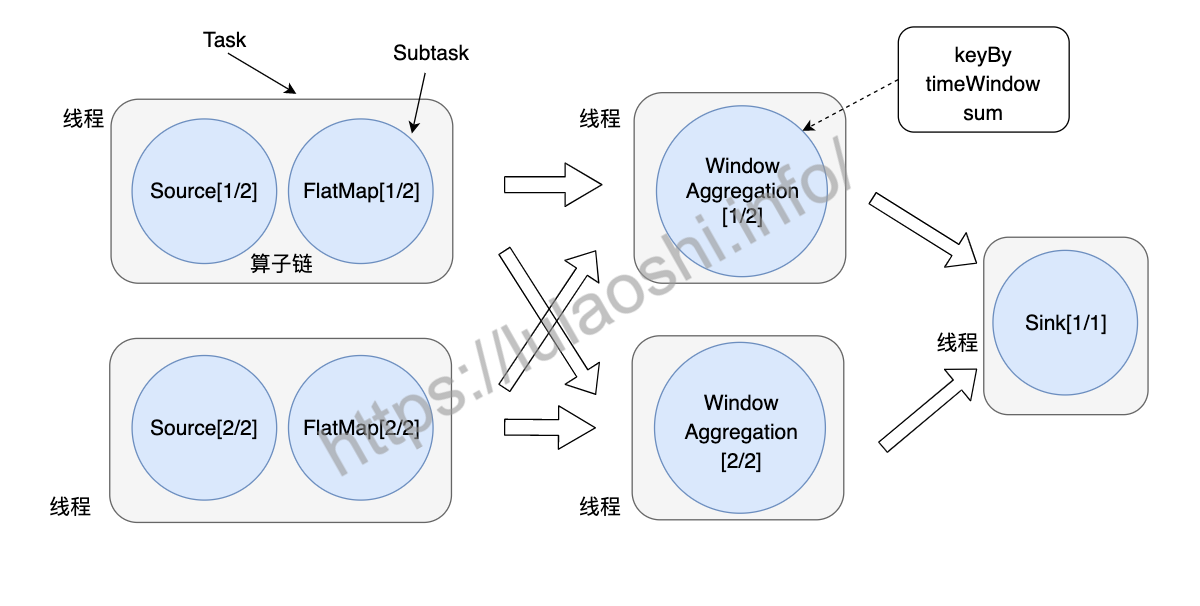
例如,数据从Source前向传播到FlatMap,这中间没有发生跨分区的数据交换,因此,我们完全可以将Source、FlatMap这两个子任务组合在一起,形成一个Task。数据经过keyBy()发生了数据交换,数据会跨越分区,因此无法将keyBy()以及其后面的窗口聚合链接到一起。由于WindowAggregation的并行度是2,Sink的并行度为1,数据再次发生了交换,我们不能把WindowAggregation和Sink两部分链接到一起。本章第一节中提到,Sink的并行度被人为设置为1,如果我们把Sink的并行度也设置为2,那么是可以让这两个算子链接到一起的。
默认情况下,Flink会尽量将更多的子任务链接在一起,这样能减少一些不必要的数据传输开销。但一个子任务有超过一个输入或发生数据交换时,链接就无法建立。两个算子能够链接到一起是有一些规则的,感兴趣的读者可以阅读Flink源码中org.apache.flink.streaming.api.graph.StreamingJobGraphGenerator中的isChainable方法。StreamingJobGraphGenerator类的作用是将StreamGraph转换为JobGraph。
尽管将算子链接到一起会降低一些传输开销,但是也有一些情况并不需要太多链接。比如,有时候我们需要将一个非常长的算子链拆开,这样我们就可以将原来集中在一个线程中的计算拆分到多个线程中来并行计算。Flink允许开发者手动配置是否启用算子链,或者对哪些算子使用算子链。我们也将在9.3.1讨论算子链的具体使用方法。
任务槽位与计算资源
Task Slot
根据前文的介绍,我们已经了解到TaskManager负责具体的任务执行。在程序执行之前,经过优化,部分子任务被链接在一起,组成一个Task。TaskManager是一个JVM进程,在TaskManager中可以并行运行一到多个Task。每个Task是一个线程,需要TaskManager为其分配相应的资源,TaskManager使用Task Slot给Task分配资源。
在解释Flink的Task Slot的概念前,我们先回顾一下进程与线程的概念。在操作系统层面,进程(Process)是进行资源分配和调度的一个独立单位,线程(Thread)是CPU调度的基本单位。比如,我们常用的Office Word软件,在启动后就占用操作系统的一个进程。Windows上可以使用任务管理器来查看当前活跃的进程,Linux上可以使用top命令来查看。线程是进程的一个子集,一个线程一般专注于处理一些特定任务,不独立拥有系统资源,只拥有一些运行中必要的资源,如程序计数器。一个进程至少有一个线程,也可以有多个线程。多线程场景下,每个线程都处理一小个任务,多个线程以高并发的方式同时处理多个小任务,可以提高处理能力。
回到Flink的槽位分配机制上,一个TaskManager是一个进程,TaskManager可以管理一至多个Task,每个Task是一个线程,占用一个Slot。每个Slot的资源是整个TaskManager资源的子集,比如下图里的TaskManager下有3个Slot,每个Slot占用TaskManager 1/3的内存,第一个Slot中的Task不会与第二个Slot中的Task互相争抢内存资源。
信息
在分配资源时,Flink并没有将CPU资源明确分配给各个槽位。
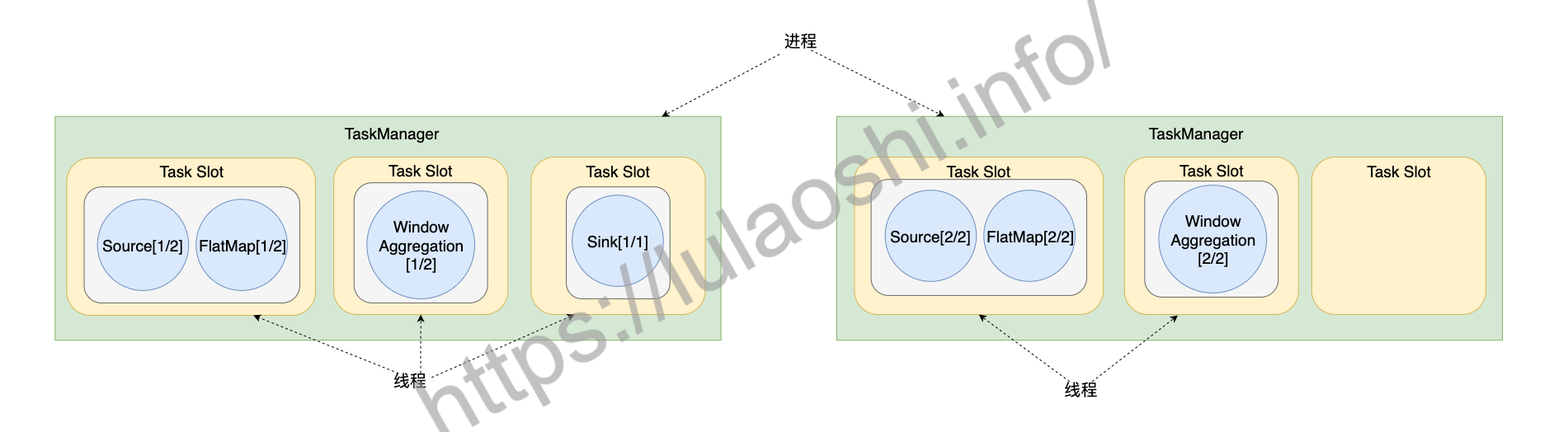
假设我们给WordCount程序分配两个TaskManager,每个TaskManager又分配3个槽位,所以共有6个槽位。结合之前图中对这个作业的并行度设置,整个作业被划分为5个Task,使用5个线程,这5个线程可以按照上图所示的方式分配到6个槽位中。
Flink允许用户设置TaskManager中槽位的数目,这样用户就可以确定以怎样的粒度将任务做相互隔离。如果每个TaskManager只包含一个槽位,那么运行在该槽位内的任务将独享JVM。如果TaskManager包含多个槽位,那么多个槽位内的任务可以共享JVM资源,比如共享TCP连接、心跳信息、部分数据结构等。官方建议将槽位数目设置为TaskManager下可用的CPU核心数,那么平均下来,每个槽位都能平均获得1个CPU核心。
槽位共享
之前的图展示了任务的一种资源分配方式,默认情况下, Flink还提供了一种槽位共享(Slot Sharing)的优化机制,进一步优化数据传输开销,充分利用计算资源。将之前图中的任务做槽位共享优化后,结果如下图所示。
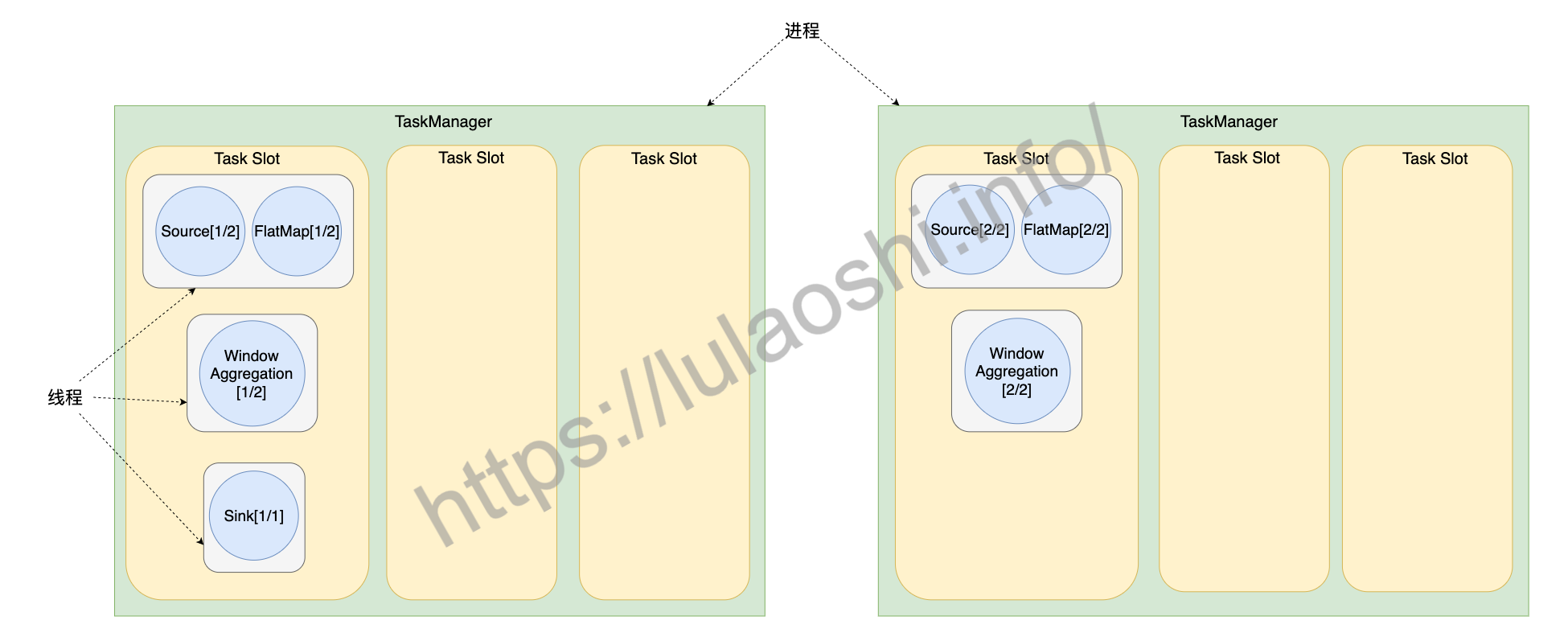
开启槽位共享后,Flink允许多个Task共享一个槽位。如上图中最左侧的数据流,一个作业从Source到Sink的所有子任务都可以放置在一个槽位中,这样数据交换成本更低。而且,对于一个数据流图来说,Source、FlatMap等算子的计算量相对不大,WindowAggregation算子的计算量比较大,计算量较大的算子子任务与计算量较小的算子子任务可以互补,腾出更多的槽位,分配给更多Task,这样可以更好地利用资源。如果不开启槽位共享,如之前图所示,计算量小的Source、FlatMap算子子任务独占槽位,造成一定的资源浪费。
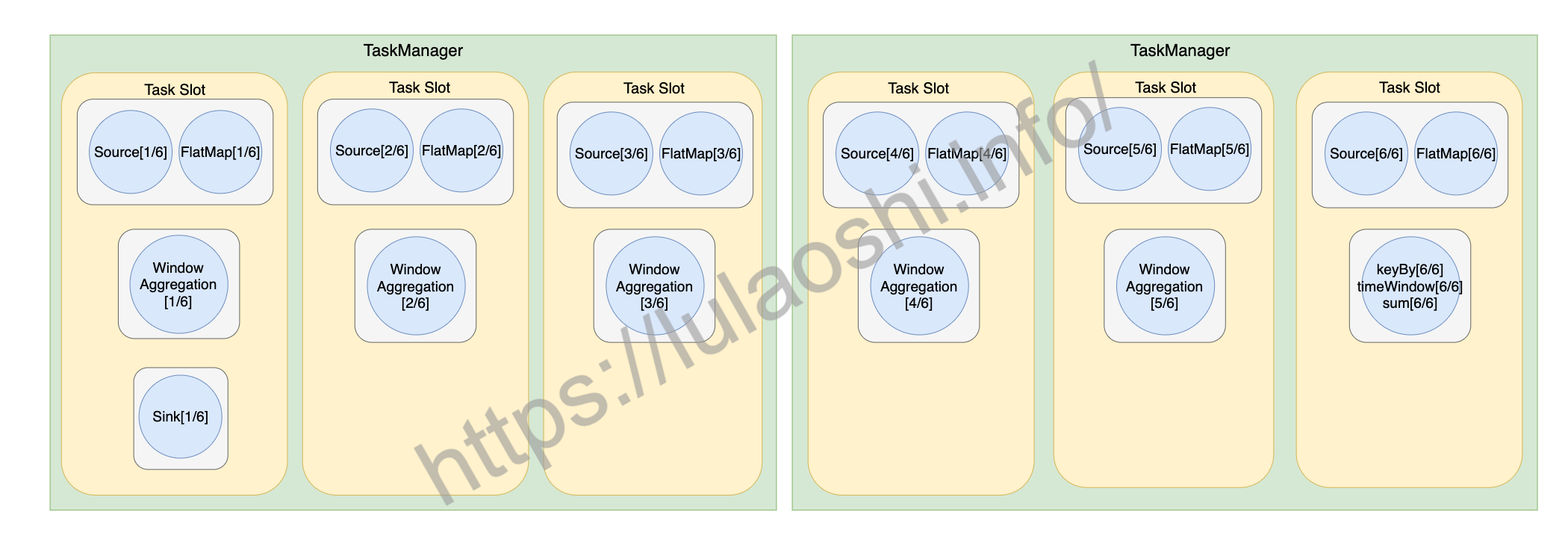
最初图中的方式共占用5个槽位,支持槽位共享后,上上图只占用2个槽位。为了充分利用空槽位,剩余的4个空槽位可以分配给别的作业,也可以通过修改并行度来分配给这个作业。例如,这个作业的输入数据量非常大,我们可以把并行度设为6,更多的算子实例会将这些槽位填充,如上图所示。
综上,Flink的一个槽位中可能运行一个算子子任务、也可以是被链接的多个子任务组成的Task,或者是共享槽位的多个Task,具体这个槽位上运行哪些计算由算子链和槽位共享两个优化措施决定。我们将在9.3节再次讨论算子链和槽位共享这两个优化选项。
并行度和槽位数目的概念可能容易让人混淆,这里再次阐明一下。用户使用Flink提供的API算子可以构建一个逻辑视图,需要将任务并行才能被物理执行。一个算子将被切分为多个子任务,每个子任务处理整个作业输入数据的一部分。如果输入数据过大,增大并行度可以让算子切分为更多的子任务,加快数据处理速度。可见,并行度是Flink对任务并行切分的一种描述。槽位数目是在资源设置时,对单个TaskManager的资源切分粒度。