Flink基础应用
基础搭建运行
-
搭建基础项目
mvn archetype:generate \ -DarchetypeGroupId=org.apache.flink \ -DarchetypeArtifactId=flink-quickstart-java \ -DarchetypeCatalog=https://repository.apache.org/content/repositories/snapshots/ \ -DarchetypeVersion=1.14.6 \ -DgroupId=wiki-edits \ -DartifactId=wiki-edits \ -Dversion=0.1 \ -Dpackage=demo \ -DinteractiveMode=falsewindow环境下的cmd或者powershell下执行下述命令
mvn org.apache.maven.plugins:maven-archetype-plugin:2.4:generate "-DarchetypeGroupId=org.apache.flink" "-DarchetypeArtifactId=flink-quickstart-java" "-DarchetypeCatalog=https://repository.apache.org/content/repositories/snapshots/" "-DarchetypeVersion=1.7-SNAPSHOT" "-DgroupId=wiki-edits" "-DartifactId=wiki-edits" "-Dversion=0.1" "-Dpackage=demo" "-DinteractiveMode=false" -
Flink启动运行
- 下载并编译
从我们的某个存储库克隆源代码,例如:
$ git clone https://github.com/apache/flink.git $ cd flink $ mvn clean package -DskipTests # this will take up to 10 minutes $ cd build-target # this is where Flink is installed to- 启动本地Flink群集
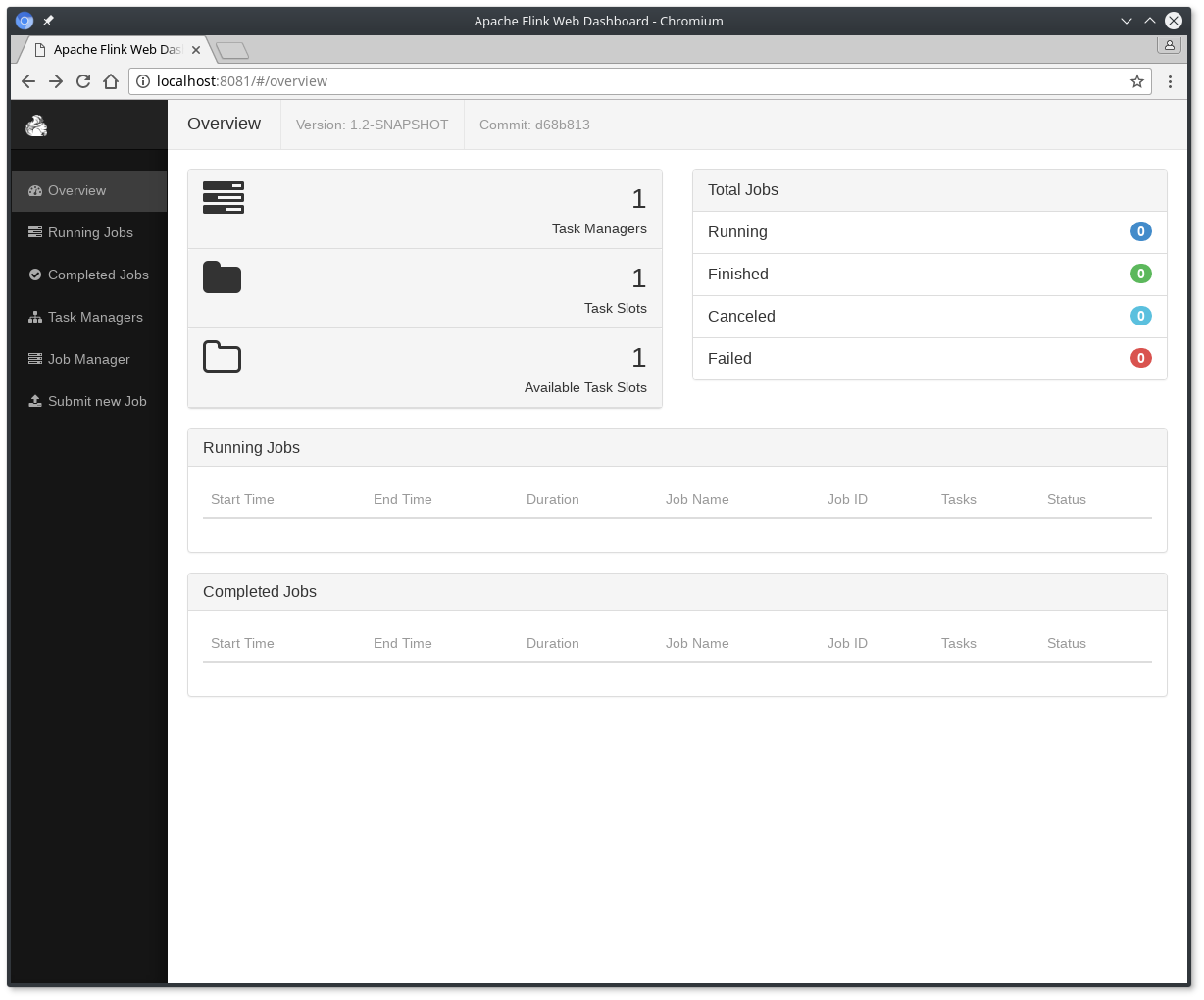
$ ./bin/start-cluster.sh # Start Flink检查分派器的web前端在HTTP://localhost:8081,并确保一切都正常运行。Web前端应报告单个可用的TaskManager实例。
您还可以通过检查
logs目录中的日志文件来验证系统是否正在运行:$ tail log/flink-*-standalonesession-*.log INFO ... - Rest endpoint listening at localhost:8081 INFO ... - http://localhost:8081 was granted leadership ... INFO ... - Web frontend listening at http://localhost:8081. INFO ... - Starting RPC endpoint for StandaloneResourceManager at akka://flink/user/resourcemanager . INFO ... - Starting RPC endpoint for StandaloneDispatcher at akka://flink/user/dispatcher . INFO ... - ResourceManager akka.tcp://[email protected]:6123/user/resourcemanager was granted leadership ... INFO ... - Starting the SlotManager.INFO ... - Dispatcher akka.tcp://[email protected]:6123/user/dispatcher was granted leadership ... INFO ... - Recovering all persisted jobs.INFO ... - Registering TaskManager ... under ... at the SlotManager. -
运算实验代码
public class SocketWindowWordCount { public static void main(String[] args) throws Exception { // the port to connect to final int port; try { final ParameterTool params = ParameterTool.fromArgs(args); port = params.getInt("port"); } catch (Exception e) { System.err.println("No port specified. Please run 'SocketWindowWordCount --port <port>'"); return; } // get the execution environment final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // get input data by connecting to the socket DataStream<String> text = env.socketTextStream("localhost", port, "\n"); // parse the data, group it, window it, and aggregate the counts DataStream<WordWithCount> windowCounts = text .flatMap(new FlatMapFunction<String, WordWithCount>() { @Override public void flatMap(String value, Collector<WordWithCount> out) { for (String word : value.split("\\s")) { out.collect(new WordWithCount(word, 1L)); } } }) .keyBy("word") .timeWindow(Time.seconds(5), Time.seconds(1)) .reduce(new ReduceFunction<WordWithCount>() { @Override public WordWithCount reduce(WordWithCount a, WordWithCount b) { return new WordWithCount(a.word, a.count + b.count); } }); // print the results with a single thread, rather than in parallel windowCounts.print().setParallelism(1); env.execute("Socket Window WordCount"); } // Data type for words with count public static class WordWithCount { public String word; public long count; public WordWithCount() {} public WordWithCount(String word, long count) { this.word = word; this.count = count; } @Override public String toString() { return word + " : " + count; } } } -
运行示例
现在,我们将运行此Flink应用程序。它将从套接字读取文本,并且每5秒打印一次前5秒内每个不同单词的出现次数,即处理时间的翻滚窗口,只要文字漂浮在其中。
- 首先,我们使用netcat来启动本地服务器
$ nc -l 9000- 提交Flink计划:
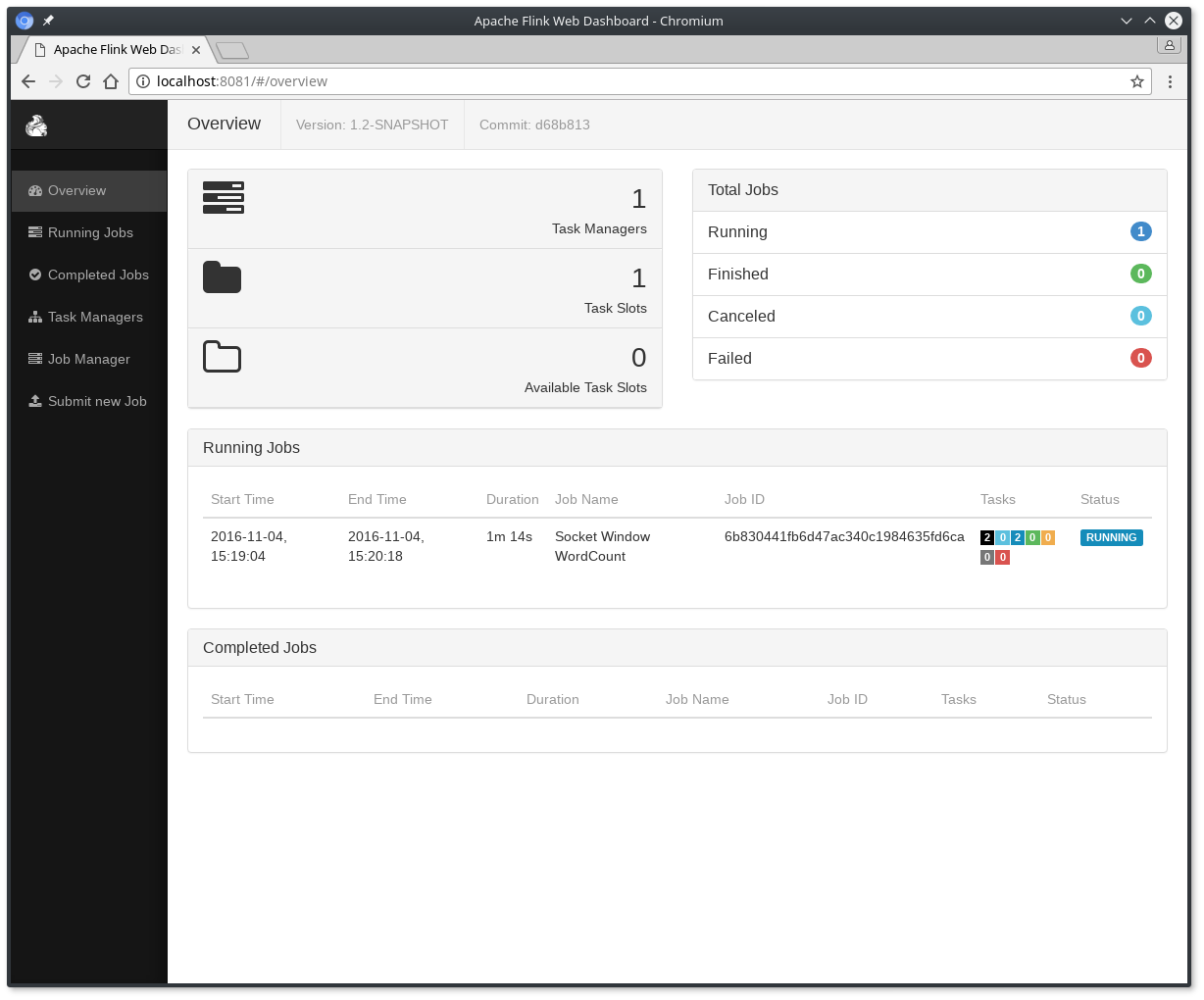
$ ./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000Starting execution of program程序连接到套接字并等待输入。您可以检查Web界面以验证作业是否按预期运行:
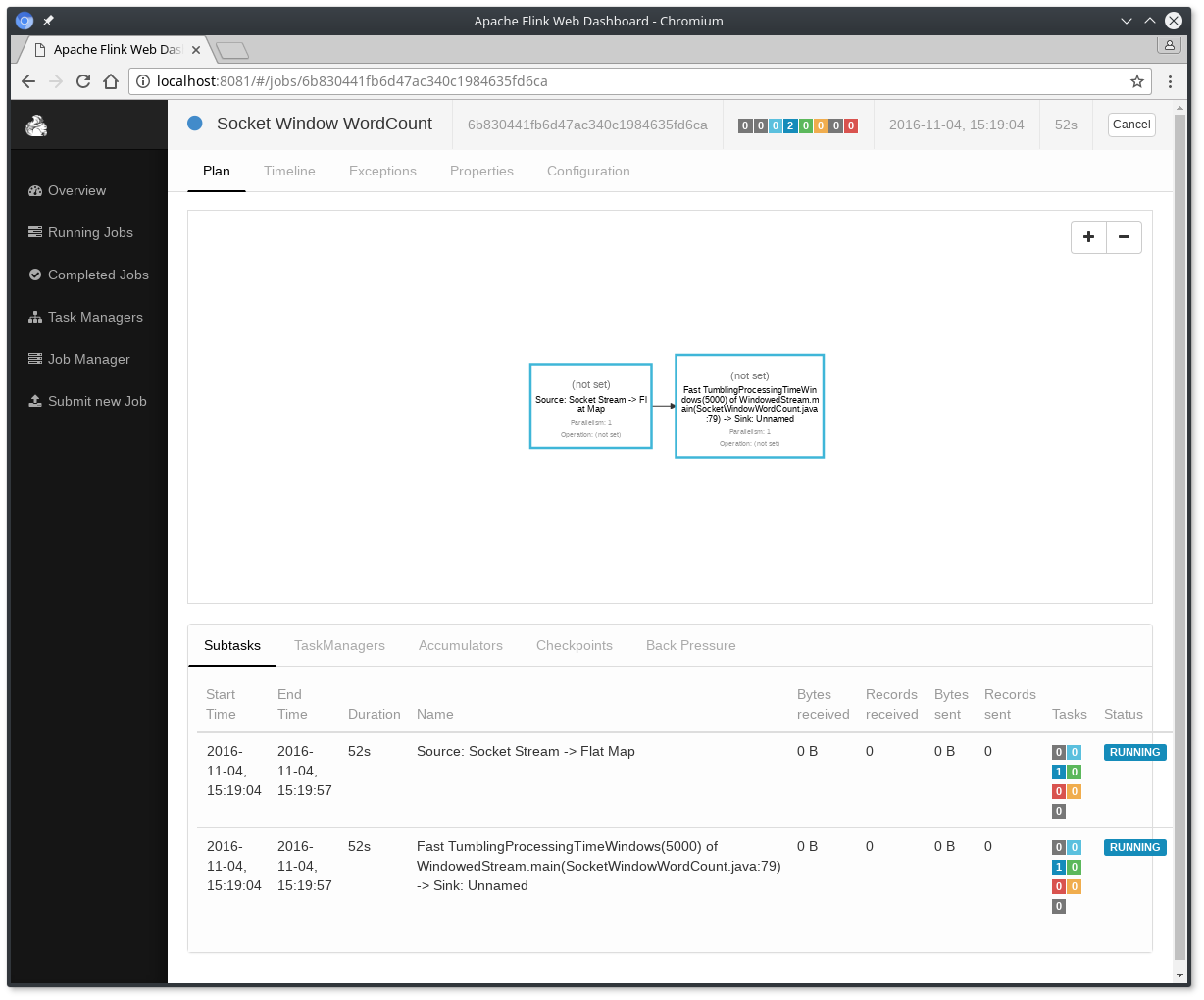
- 单词在5秒的时间窗口(处理时间,翻滚窗口)中计算并打印到
stdout。监视TaskManager的输出文件并写入一些文本nc(输入在点击后逐行发送到Flink):
$ nc -l 9000lorem ipsumipsum ipsum ipsumbye该
.out文件将在每个时间窗口结束时,只要打印算作字浮在,例如:$ tail -f log/flink-*-taskexecutor-*.outlorem : 1bye : 1ipsum : 4要停止Flink当你做类型:
复制代码$ ./bin/stop-cluster.sh


独立运行代码示例
自带flink
POM依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>wiki-edits</groupId>
<artifactId>wiki-edits</artifactId>
<version>0.1</version>
<packaging>jar</packaging>
<name>Flink Quickstart Job</name>
<url>https://www.myorganization.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
<flink.version>1.14.6</flink.version>
<scala.binary.version>1.14.6</scala.binary.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
</properties>
<dependencies>
<!-- Apache Flink 核心依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- Apache Flink 流批处理依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${scala.binary.version}</version>
<scope>provided</scope>
</dependency>
<!-- Apache Flink 连接器依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>${scala.binary.version}</version>
<exclusions>
<exclusion>
<artifactId>lz4-java</artifactId>
<groupId>org.lz4</groupId>
</exclusion>
<exclusion>
<artifactId>slf4j-api</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
<exclusion>
<artifactId>snappy-java</artifactId>
<groupId>org.xerial.snappy</groupId>
</exclusion>
</exclusions>
</dependency>
<!-- Apache Flink web依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_2.12</artifactId>
<version>${scala.binary.version}</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>apache.snapshots</id>
<name>Apache Development Snapshot Repository</name>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
</configuration>
</plugin>
<!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. -->
<!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.0.0</version>
<executions>
<!-- Run shade goal on package phase -->
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.flink:force-shading</exclude>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>demo.stream.StreamingJob</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
<!-- This profile helps to make things run out of the box in IntelliJ -->
<!-- Its adds Flink's core classes to the runtime class path. -->
<!-- Otherwise they are missing in IntelliJ, because the dependency is 'provided' -->
<profiles>
<profile>
<id>add-dependencies-for-IDEA</id>
<activation>
<property>
<name>idea.version</name>
</property>
</activation>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${scala.binary.version}</version>
<scope>compile</scope>
</dependency>
</dependencies>
</profile>
</profiles>
</project>JAVA代码
package demo;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
/**
* WordCount
*
* @author lukelee
* @date 2022/12/15
*/
public class SocketWindowWordCount {
public static void main(String[] args) throws Exception {
// the port to connect to
final int port;
try {
final ParameterTool params = ParameterTool.fromArgs(args);
port = params.getInt("port");
} catch (Exception e) {
System.err.println("No port specified. Please run 'SocketWindowWordCount --port <port>'");
return;
}
// 访问http://localhost:8082 可以看到Flink Web UI
Configuration conf = new Configuration();
conf.setInteger(RestOptions.PORT, 8082);
// 创建本地执行环境,并行度为2
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(2, conf);
// 不启动窗口
// final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 远程提交任务
// StreamExecutionEnvironment env = StreamExecutionEnvironment.createRemoteEnvironment("gcw1", 8081);
// StreamTableEnvironment stEnv = StreamTableEnvironment.create(env);
// get input data by connecting to the socket
DataStream<String> text = env.socketTextStream("localhost", port, "\n");
// parse the data, group it, window it, and aggregate the counts
DataStream<WordWithCount> windowCounts = text
.flatMap((FlatMapFunction<String, WordWithCount>) (value, out) -> {
for (String word : value.split("\\s")) {
out.collect(new WordWithCount(word, 1L));
}
})
.keyBy(data -> data.word)
// 添加滑动窗口,采用处理时间进行处理
.window(SlidingProcessingTimeWindows.of(Time.seconds(5), Time.seconds(1)))
// 添加滚动窗口 ,采用事件时间进行处理
// .window(TumblingEventTimeWindows.of(Time.seconds(8)))
// 历史版本 <=1.10
// .keyBy("word")
// .timeWindow(Time.seconds(5), Time.seconds(1))
.reduce((ReduceFunction<WordWithCount>) (a, b) -> new WordWithCount(a.word, a.count + b.count));
// print the results with a single thread, rather than in parallel
windowCounts.print().setParallelism(1);
env.execute("Socket Window WordCount");
}
/**
* Data type for words with count
*/
public static class WordWithCount {
public String word;
public long count;
public WordWithCount(String word, long count) {
this.word = word;
this.count = count;
}
@Override
public String toString() {
return word + " : " + count;
}
}
}
Flink原理简介
数据流向
上一章的案例中,我们尝试构建了一个文本数据流管道,这个Flink程序可以计算数据流中单词出现的频次。如果输入数据流是“Hello Flink Hello World“,这个程序将统计出“Hello”的频次为2,“Flink”和“World”的频次为1。在大数据领域,WordCount程序就像是一个编程语言的HelloWorld程序,它展示了一个大数据引擎的基本规范。麻雀虽小,五脏俱全,从这个样例中,我们可以一窥Flink设计和运行原理。
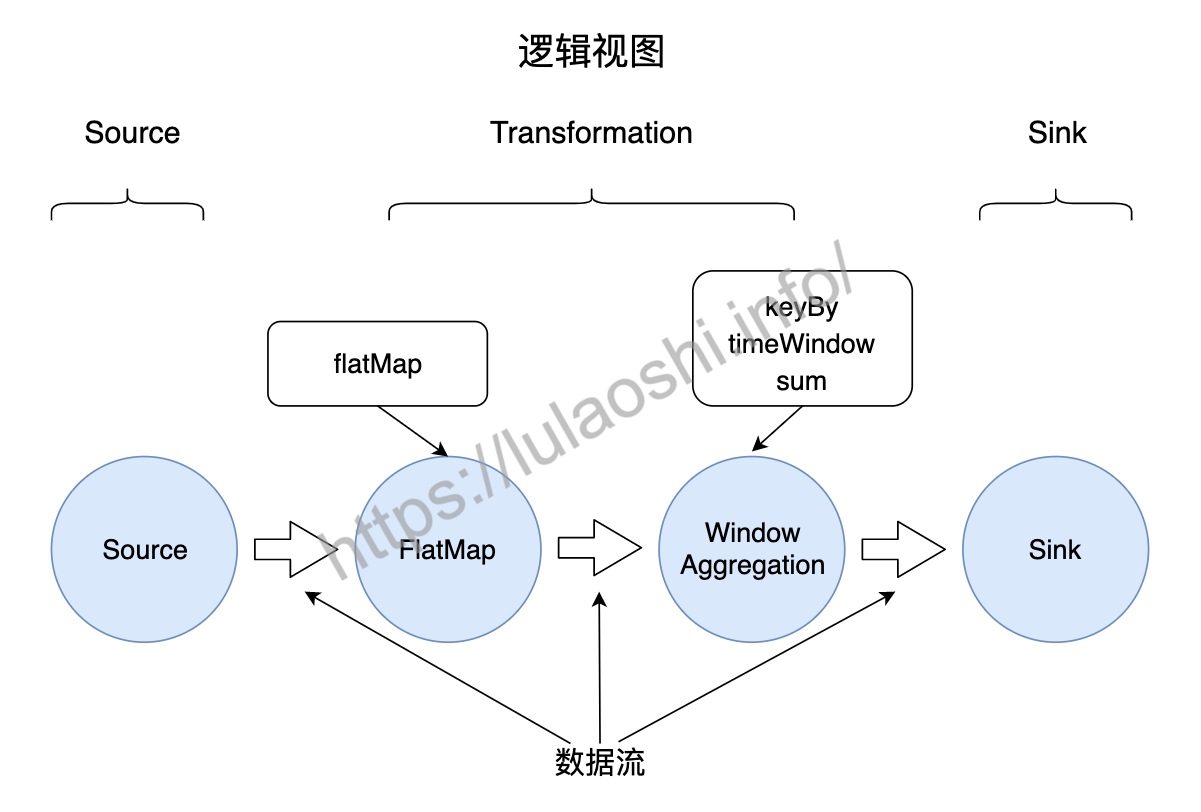
如下图所示,程序分为三大部分,第一部分读取数据源(Source),第二部分对数据做转换操作(Transformation),最后将转换结果输出到一个目的地(Sink)。

代码中的方法被称为函数(Function),是Flink提供给程序员的接口,程序员需要调用并实现这些函数,对数据进行操作,进而完成特定的业务逻辑。通常一到多个函数会组成一个算子(Operator), 算子执行对数据的操作(Operation)。在WordCount的例子中,有三类算子:Source算子读取数据源中的数据,数据源可以是数据流、也可以存储在文件系统中的文件。Transformation算子对数据进行必要的计算处理。Sink算子将处理结果输出,数据一般被输出到数据库、文件系统或下一个数据流程序。
我们可以把算子理解为1 + 2 运算中的加号,加号(+)是这个算子的一个符号表示,它表示对数字1和数字2做加法运算。同样,在Flink或Spark这样的大数据引擎中,算子对数据进行某种操作,程序员可以根据自己的需求调用合适的算子,完成所需计算任务。Flink常用的算子有map()、flatMap()、keyBy()、timeWindow()等,它们分别对数据流执行不同类型的操作。
我们先对这个样例程序中各个算子做一个简单的介绍,关于这些算子的具体使用方式将在后续章节中详细说明。
- flatMap
flatMap()对输入进行处理,生成零到多个输出。本例中它执行一个简单的分词过程,对一行字符串按照空格切分,生成一个(word, 1)的二元组。
- keyBy
keyBy()根据某个Key对数据重新分组。本例中是将二元组(word, 1)中第一项作为Key进行分组,相同的单词会被分到同一组。
- timeWindow
timeWindow()是时间窗口函数,用来界定对多长时间之内的数据做统计。
- sum
sum()为求和函数。sum(1)表示对二元组中第二个元素求和,因为经过前面的keyBy,所有相同的单词都被分到了一组,因此,在这个分组内,将单词出现次数做加和,就得到出现的总次数。
在程序实际运行前,Flink会将用户编写的代码做一个简单处理,生成一个如下图所示的逻辑视图。下图展示了WordCount程序中,数据从不同算子间流动的情况。图中,圆圈代表算子,圆圈间的箭头代表数据流,数据流在Flink程序中经过不同算子的计算,最终生成结果。其中,keyBy()、timeWindow()和sum()共同组成了一个时间窗口上的聚合操作,被归结为一个算子。我们可以在Flink的Web UI中,点击一个作业,查看这个作业的逻辑视图。
对于词频统计这个案例,逻辑上来讲无非是对数据流中的单词做提取,然后使用一个Key-Value结构对单词做词频计数,最后输出结果即可,这样的逻辑本可以用几行代码完成,改成使用算子形式,反而让新人看着一头雾水,为什么一定要用算子的形式来写程序呢?实际上,算子进化成当前这个形态,就像人类从石块计数,到手指计数,到算盘计数,再到计算机计数这样的进化过程一样,尽管更低级的方式可以完成一定的计算任务,但是随着计算规模的增长,古老的计数方式存在着低效的弊端,无法完成更高级别和更大规模的计算需求。试想,如果我们不使用大数据框架提供的算子,而是自己实现一套上述的计算逻辑,尽管我们可以快速完成当前的词频统计的任务,但是当面临一个新计算任务时,我们需要重新编写程序,完成一整套计算任务。我们自己编写代码的横向扩展性可能很低,当输入数据暴增时,我们需要做很大改动,以部署在更多机器上。
大数据引擎的算子对计算做了一些抽象,对于新人来说有一定学习成本,而一旦掌握这门技术,人们所能处理的数据规模将成倍增加。算子的出现,正是针对大数据场景下,人们需要一种统一的计算描述语言来对数据做计算而进化出的新计算形态。基于Flink的算子,我们可以定义一个数据流的逻辑视图,以此完成对大数据的计算。剩下那些数据交换、横向扩展、故障恢复等问题全交由大数据引擎来解决。
从逻辑视图到物理执行
在绝大多数的大数据处理场景下,一台机器节点无法处理所有数据,数据被切分到多台节点上。在大数据领域,当数据量大到超过单台机器处理能力时,需要将一份数据切分到多个分区(Partition)上,每个分区分布在一台虚拟机或物理机上。
前一小节已经提到,大数据引擎的算子提供了编程接口,我们可以使用算子构建数据流的逻辑视图。考虑到数据分布在多个节点的情况,逻辑视图只是一种抽象,需要将逻辑视图转化为物理执行图,才能在分布式环境下执行。
下图为WordCount程序的物理执行示意图,数据流分布在2个分区上。箭头部分表示数据流分区,圆圈部分表示算子在分区上的算子子任务(Operator Subtask)。从逻辑视图变为物理执行图后,FlatMap算子在每个分区都有一个算子子任务,以处理该分区上的数据:FlatMap[1/2]算子子任务处理第一个数据流分区上的数据,以此类推。
<<<<<<< HEAD
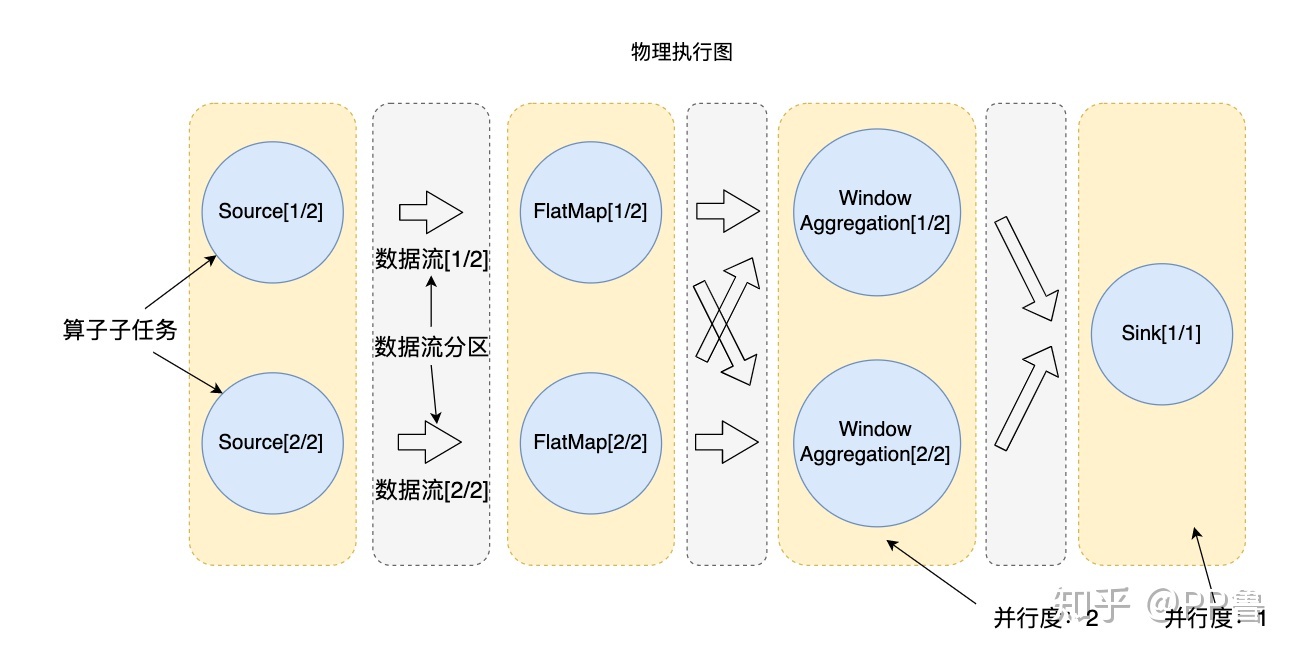

8bdbbd835ea1e4a778da30e70ef7bc8fc2af8844
在分布式计算环境下,执行计算的单个节点(物理机或虚拟机)被称为实例,一个算子在并行执行时,算子子任务会分布到多个节点上,所以算子子任务又被称为算子实例(Instance)。即使输入数据增多,我们也可以通过部署更多的算子实例来进行横向扩展。从图 3‑3中可以看到,除去Sink外的算子都被分成了2个算子实例,他们的并行度(Parallelism)为2,Sink算子的并行度为1。并行度是可以被设置的,当设置某个算子的并行度为2时,也就意味着这个算子有2个算子子任务(或者说2个算子实例)并行执行。实际应用中一般根据输入数据量的大小,计算资源的多少等多方面的因素来设置并行度。
信息
在本例中,为了演示,我们把所有算子的并行度设置为了2:env.setParallelism(2);,把Sink的并行度设置成了1:wordCount.print().setParallelism(1);。如果不单独设置print的并行度的话,它的并行度也是2。
算子子任务是Flink物理执行的基本单元,算子子任务之间是相互独立的,某个算子子任务有自己的线程,不同算子子任务可能分布在不同的机器节点上。后文在Flink的资源分配部分我们还会重点介绍算子子任务。
在本书后文的描述中,算子子任务、分区、实例都是指对算子的并行切分。
数据交换策略
下图中出现了数据流动的现象,即数据在不同的算子子任务上进行着数据交换。无论是Hadoop、Spark还是Flink,都会涉及到数据交换策略。常见的据交换策略有4种,如下图所示。

- 前向传播(Forward):前一个算子子任务将数据直接传递给后一个算子子任务,数据不存在跨分区的交换,也避免了因数据交换产生的各类开销,图 3‑3中Source和和FlatMap之间就是这样的情形。
- 按Key分组(Key-Based):数据以(Key, Value)形式存在,该策略将所有数据按照Key进行分组,相同Key的数据会被分到一组,发送到同一个分区上。WordCount程序中,keyBy将单词作为Key,把相同单词都发送到同一分区,以方便后续算子的聚合统计。
- 广播(Broadcast):将某份数据发送到所有分区上,这种策略涉及到了数据在全局的拷贝,因此非常消耗资源。
- 随机策略(Random):该策略将所有数据随机均匀地发送到多个分区上,以保证数据平均分配到不同分区上。该策略通常为了防止数据倾斜到某些分区,导致部分分区数据稀疏,另外一些分区数据拥堵。