二叉树与多路树(B树)
算法复杂度
二叉查找树(BST)
-
左子树上所有结点的值均小于或等于它的根结点的值。
-
右子树上所有结点的值均大于或等于它的根结点的值。
-
左、右子树也分别为二叉排序树。
查找结点里面的值 的方式就是二分查找的思想 查找次数就是树的高度,查找的时间复杂度为 O(logn)。
极端情况时,二叉查找树已经近似退化为一条链表,其查找的时间复杂度为 O(n),故而引入平衡二叉树解决问题。
平衡二叉树(AVL Tree)
-
具有二叉查找树的全部特性。
- 每个节点的左子树和右子树的高度差至多等于1。
对于有 n 个节点的平衡树,最坏的查找时间复杂度也为 O(logn)。
-
缺点:
因为平衡树要求每个节点的左子树和右子树的高度差至多等于1,这个要求实在是太严了,导致每次进行插入/删除节点的时候,几乎都会破坏平衡树的第二个规则,进而我们都需要通过左旋和右旋来进行调整,使之再次成为一颗符合要求的平衡树。
在那种插入、删除很频繁的场景中,平衡树需要频繁着进行调整,这会使平衡树的性能大打折扣,故而引入红黑树解决问题。
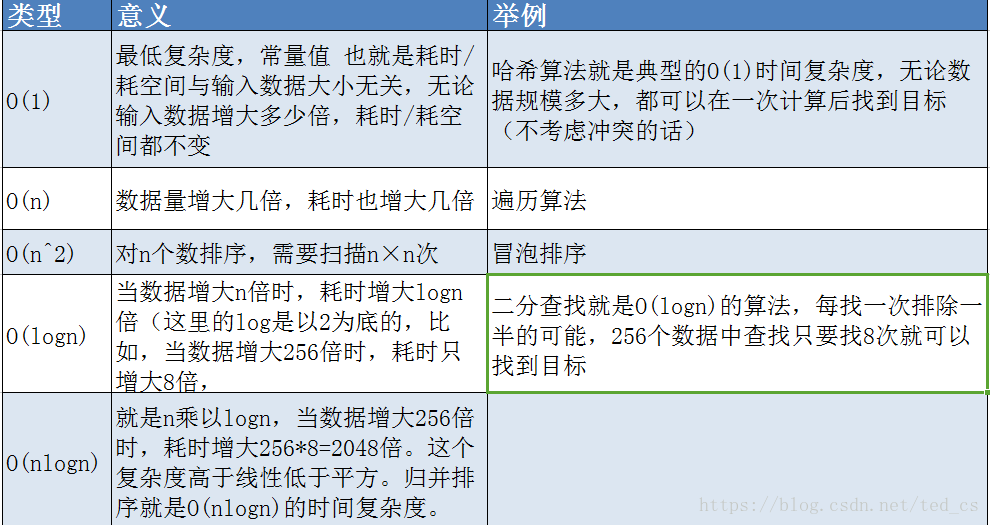
红黑树
-
节点是红色或黑色。
-
根节点是黑色。
-
每个叶子节点都是黑色的空节点(是指为空(NIL或NULL)的叶子节点, 最底部)。
-
每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
红黑树是一种平衡树,他复杂的定义和规则都是为了保证树的平衡性。
JAVA中使用到红黑树的有TreeSet和JDK1.8的HashMap。
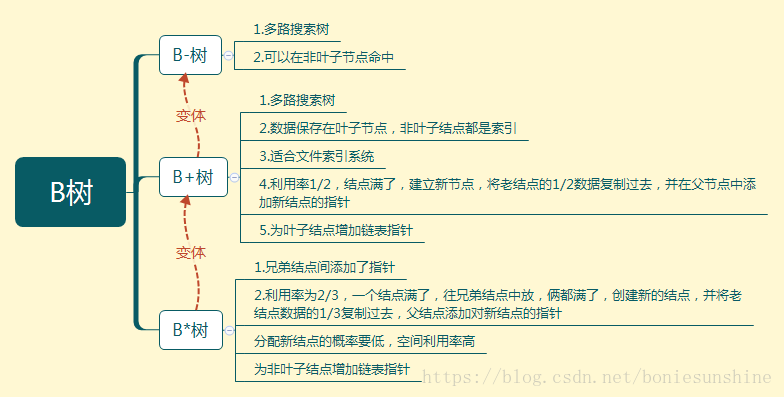
B树
B-tree树即B树,B即Balanced,平衡的意思。因为B树的原英文名称为B-tree,而国内很多人喜欢把B-tree译作B-树,其实,这是个非常不好的直译,很容易让人产生误解。如人们可能会以为B-树是一种树,而B树又是另一种树。而事实上是,B-tree就是指的B树。
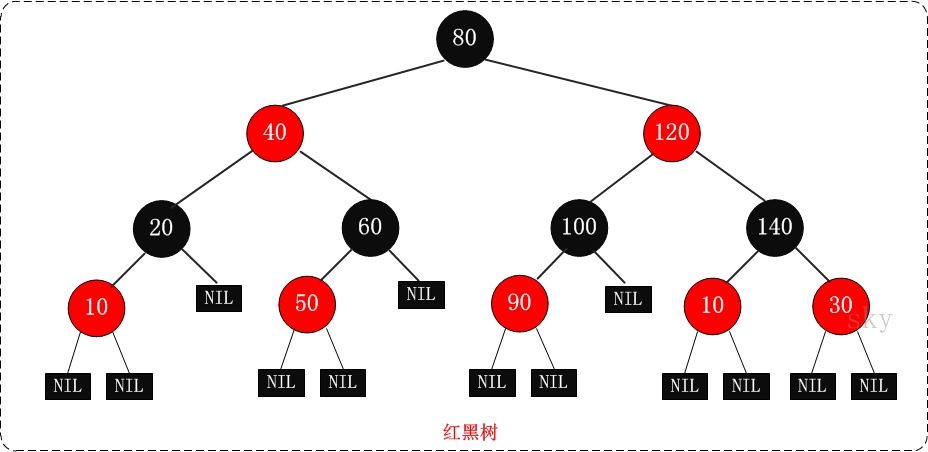
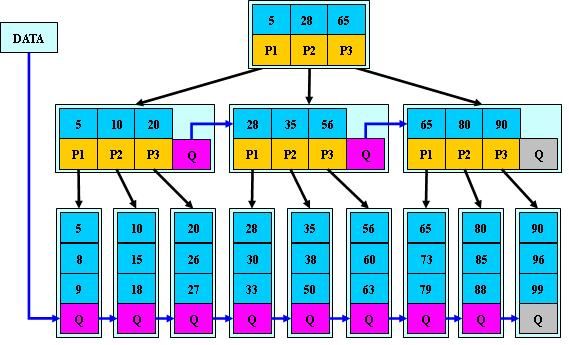
B树(B-树)是一种多路搜索树(并不是二叉的):
- 定义任意非叶子结点最多只有M个儿子;且M>2;
- 根结点的儿子数为[2, M];
- 除根结点以外的非叶子结点的儿子数为[M/2, M];
- 每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
- 非叶子结点的关键字个数=指向儿子的指针个数-1;
- 非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
- 非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
-
所有叶子结点位于同一层;
如:(M=3)
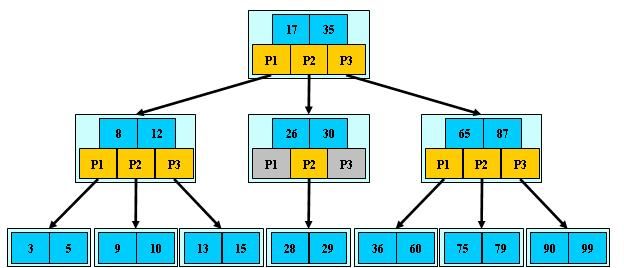
B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
B-树的特性:
- 关键字集合分布在整颗树中;
- 任何一个关键字出现且只出现在一个结点中;
- 搜索有可能在非叶子结点结束;
- 其搜索性能等价于在关键字全集内做一次二分查找;
- 自动层次控制;
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的利用率;
所以B-树的性能等价于二分查找(与M值无关),也就没有B树平衡的问题;
- 由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
使用场景
-
为什么要用B树,红黑树不是就挺好的么? B树和二叉树、红黑树相比较,子树更多也就是路数越多,子树月多表示数的高度越低,搜索效率越高,当然如果路数太多就可能变成一个有序数组了。所以当然不可能使得路数无限大。
正因为文件系统和数据库一般都是存在电脑硬盘上的,如果数据量太大的话不一定能一次性加载到内存中。(一棵树不能一次性加载完怎么查找对吧?)但是B树可以多路存储。也正因为B树的这一个优点,可以在文件查找的时候每次只加载一个节点的内容存入内存来查找。而红黑树在内存中查找非常块,但是如果在数据库和文件系统中,显然B树更优。
B+树
B+树是B-树的变体,也是一种多路搜索树,其定义基本与B-树同,除了:
- 非叶子结点的子树指针与关键字个数相同;
- 非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
- 为所有叶子结点增加一个链指针;
- 所有关键字都在叶子结点出现;
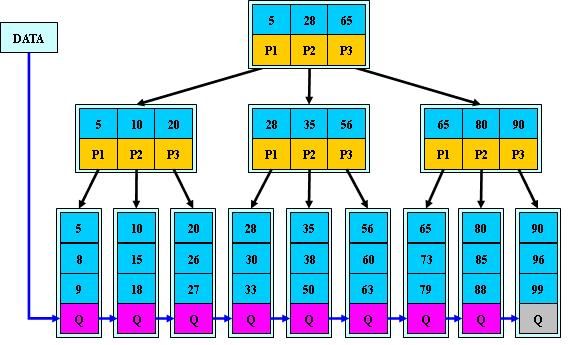
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
- 所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
- 不可能在非叶子结点命中;
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
- 更适合文件索引系统;
使用场景:
B+ 树通常用于数据库和操作系统的文件系统中。NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系统都在使用B+树作为元数据索引。B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+ 树元素自底向上插入。
B*树
是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;
B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2);
B+变体原因:
-
B+树的分裂:
-
当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;
- B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
-
- B*树的分裂:
- 当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);
- 如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
多路树对比
小结
-
二叉搜索树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于走右结点;
-
B树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;B-树是一种平衡的多路查找(又称排序)树,在文件系统中有所应用。主要用作文件的索引。其中的B就表示平衡(Balance);
-
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;B+树有一个最大的好处,方便扫库,B树必须用中序遍历的方法按序扫库,而B+树直接从叶子结点挨个扫一遍就完了。B+树支持range-query(区间查询)非常方便,而B树不支持。这是数据库选用B+树的最主要原因。
- B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3;
简而言之:
B-tree:有序数组+平衡多叉树;
B+-tree:有序数组链表+平衡多叉树;
B*-tree:一棵丰满的B+-tree。