Elasticsearch原理及使用
Elastic Stack简单架构说明
- Kibana 数据可视化组件
- Beats 轻量级数据采集工具
- Logstash 数据加工及采集工具
特点
- 扩展性
- 高可用性
- 灵活的数据模型(JSON)
- 快速查询
- 聚合查询语言
- 业务分析
倒排索引
一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
官网说明:https://www.elastic.co/guide/cn/elasticsearch/guide/current/inverted-index.html
分片
分片(shard): 因为 ES 是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 而这些分布在不同节点的数据就是分片. ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配, 所以用户基本上不用担心分片的处理细节.
副本(replica): ES 默认为一个索引创建 5 个主分片, 并分别为其创建一个副本分片. 也就是说每个索引都由 5 个主分片成本, 而每个主分片都相应的有一个 copy。对于分布式搜索引擎来说, 分片及副本的分配将是高可用及快速搜索响应的设计核心.主分片与副本都能处理查询请求,它们的唯一区别在于只有主分片才能处理索引请求.副本对搜索性能非常重要,同时用户也可在任何时候添加或删除副本。额外的副本能给带来更大的容量, 更高的呑吐能力及更强的故障恢复能力。
- 主分片和副本分片如何交互
为了说明目的, 我们 假设有一个集群由三个节点组成。 它包含一个叫 blogs 的索引,有两个主分片,每个主分片有两个副本分片。相同分片的副本不会放在同一节点,所以我们的集群看起来像 Figure 8, “有三个节点和一个索引的集群”。
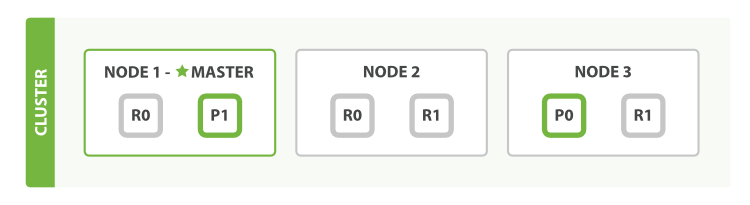
Figure 8. 有三个节点和一个索引的集群
我们可以发送请求到集群中的任一节点。 每个节点都有能力处理任意请求。 每个节点都知道集群中任一文档位置,所以可以直接将请求转发到需要的节点上。 在下面的例子中,将所有的请求发送到 Node 1 ,我们将其称为 协调节点(coordinating node) 。
路由一个文档到一个分片中
当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 1 还是分片 2 中呢?
首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:
shard = hash(routing) % number_of_primary_shardsrouting 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到 余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
这就解释了为什么我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
常规扩容
分片预分配
一个分片存在于单个节点,但一个节点可以持有多个分片。想象一下我们创建拥有两个主分片的索引而不是一个:
PUT /my_index
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 0
}
}| 创建拥有两个主分片无副本分片的索引。 | |
|---|---|
当只有一个节点时,两个分片都将被分配至相同的节点。 从我们应用程序的角度来看,一切都和之前一样运作着。应用程序和索引进行通讯,而不是分片,现在还是只有一个索引。
这时,我们加入第二个节点,Elasticsearch 会自动将其中一个分片移动至第二个节点,如 Figure 50, “一个拥有两个分片的索引可以利用第二个节点” 描绘的那样, 当重新分配完成后,每个分片都将接近至两倍于之前的计算能力。
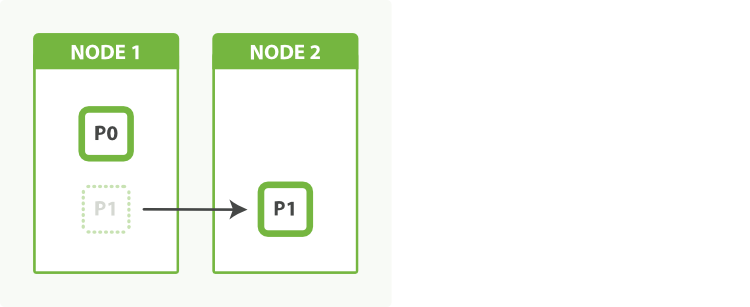
Figure 50. 一个拥有两个分片的索引可以利用第二个节点
我们已经可以通过简单地将一个分片通过网络复制到一个新的节点来加倍我们的处理能力。 最棒的是,我们零停机地做到了这一点。在分片移动过程中,所有的索引搜索请求均在正常运行。
在 Elasticsearch 中新添加的索引默认被指定了五个主分片。 这意味着我们最多可以将那个索引分散到五个节点上,每个节点一个分片。 它具有很高的处理能力,还未等你去思考这一切就已经做到了!
基于Kibana访问开发
版本8.0之后,索引与type对应关系一对一
-
创建索引及类型
POST index/_type/id
-
查询
GET index/_type/id
-
修改
PUT index/_type/id
-
通过查询修改
POST index/_update_by_query
-
常规查询
GET index/_search
查询条件
更多内容查看官网说明:https://www.elastic.co/guide/cn/elasticsearch/guide/current/structured-search.html
- 地址查询
"post_filter":{ "geo_distance":{ "distance":"5km", "location":{ "lat":39.9325, "lon":116.2658 } } }- 范围查询
"range" : { "price" : { "gte" : 20, "lte" : 40 } }- 布尔过滤器
{ "bool" : { "must" : [], "should" : [], "must_not" : [], } }- 字段搜索
//字段搜索 "BIRTHDAY HAPPY"也能搜索出来 "query":{ "match":{ "message":"HAPPY BIRTHDAY" } } //词组搜索 "query":{ "match_phrase":{ "message":"HAPPY BIRTHDAY" } } -
删除
DELETE index
-
批量插入
POST _bulk
-
查询表库结构
GET index/_mapping
字段类型
- text 可以用于全文搜索
- keyword 可以用于聚合查询,统计分析
mapping自动生成的数据结构可能出现异常,可以通过
PUT index/_mapping自定义结构.- 分词查看
GET index/_analyze
创建mapping时,可以指定分词器,或自定义