Sleuth服务链路跟踪
微服务跟踪(sleuth)其实是一个工具,它在整个分布式系统中能跟踪一个用户请求的过程(包括数据采集,数据传输,数据存储,数据分析,数据可视化),捕获这些跟踪数据,就能构建微服务的整个调用链的视图,这是调试和监控微服务的关键工具。
- Spring Cloud Sleuth有4个特点
| 特点 | 说明 |
|---|---|
| 提供链路追踪 | 通过sleuth可以很清楚的看出一个请求经过了哪些服务, 可以方便的理清服务局的调用关系。 |
| 性能分析 | 通过sleuth可以很方便的看出每个采集请求的耗时, 分析出哪些服务调用比较耗时,当服务调用的耗时 随着请求量的增大而增大时,也可以对服务的扩容提 供一定的提醒作用。 |
| 数据分析 优化链路 | 对于频繁地调用一个服务,或者并行地调用等, 可以针对业务做一些优化措施。 |
| 可视化 | 对于程序未捕获的异常,可以在zipkpin界面上看到。 |
Spring Cloud Sleuth 作用
在 Spring Boot 应用中,通过在工程中引入 spring-cloud-starter-sleuth 依赖之后,它会自动为当前应用构建起各通信通道的跟踪机制,比如:
- 通过诸如 RabbitMQ、Kafka(或者其他任何 Spring Cloud Stream 绑定器实现的消息中间件)传递的请求。
- 通过 Zuul 代理传递的请求。
- 通过 RestTemplate 发起的请求。
跟踪原理
Spring Clpud Sleuth 实现分布式系统中的服务跟踪功能,主要在于下面两个关键点:
- 为了实现请求跟踪,当请求发送到分布式系统的入口端点时,只需要服务跟踪框架为该请求创建一个唯一的跟踪标识,同时在分布式系统内部流转的时候,框架始终保持传递该唯一标识,直到返回给请求方为止。这个唯一标识就是后面会介绍到的 Trace ID。通过 Trace ID 的记录,我们就能将所有请求过程的日志关联起来。
- 为了统计各处理单元的时间延迟,当请求到达各个服务组件时,或是处理逻辑到达某个状态时,也通过一个唯一标识来标记它的开始、具体过程以及结束,该标识就是后面提到的 Span ID。对于每个 Span 来说,它必须有开始和结束两个节点,通过记录开始 Span 和结束 Span 的时间戳,就能统计出该 Span 的时间延迟,除了时司戳记录之外,它还可以包含一些其他元数据,比如事件名称、请求信息等。
准备工作
(1)在引入 Sleuth 之前,我们需要先准备三个项目:服务注册中心 eureka-server、服务提供者 hello-service、服务消费者 ribbon-consumer,具体搭建步骤可以参考我之前写的文章:
(2)其中服务提供者 hello-service 实现了一个 REST 接口 /hello:
@RestController
public class HelloController {
private final Logger logger = LoggerFactory.getLogger(getClass());
@GetMapping("/hello")
public String hello() {
logger.info("--- <call hello> ---");
return "welcome to hangge.com";
}
}(3)而服务消费者 ribbon-consumer 实现 /hello-consumer 接口,并使用 RestTemplate 调用 hello-service 应用的 /hello 接口:
@RestController
public class ConsumerController {
private final Logger logger = LoggerFactory.getLogger(getClass());
@Autowired
RestTemplate restTemplate;
@GetMapping("/hello-consumer")
public String helloConsumer() {
logger.info("--- <call hello-consumer> ---");
return restTemplate.getForEntity("http://HELLO-SERVICE/hello", String.class).getBody();
}
}(4)启动服务访问 ribbon-consumer 应用的 /hello-consumer 接口,可以看到页面结果如下:

(5)同时 ribbon-consumer 应用控制台输出如下:

(6)而 hello-service 控制台输出如下:

4,实现跟踪
(1)要增加服务跟踪功能十分简单,只需要添加 spring-cloud-starter-sleuth 依赖即可:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>(2)启动项目再次问 ribbon-consumer 应用的 /hello-consumer 接口,可以看到 ribbon-consumer 应用控制台输出如下:
从下面的控制台输出内容中,我们可以看到多了一些形如 [ribbon-consumer,081074fbd2647722,081074fbd2647722,false] 的日志信息,而这些元素正是实现分布式服务跟踪的重要组成部分,每个值的含义如下所述:
- 第一个值 ribbon-consumer:它记录了应用的名称,也就是 application.properties 中 spring.application.name 参数配置的属性。
- 第二个值 081074fbd2647722:是 Spring Cloud Sleuth 生成的一个 ID,称为 Trace ID,它用来标识一条请求链路。一条请求链路中包含一个 Trace ID,多个 Span ID。
- 第三个值 081074fbd2647722:是 Spring Cloud Sleuth 生成的另外一个 ID,称为 Span ID,它表示一个基本的工作单元,比如发送一个 HTTP 请求。
- 第四个值 false:表示是否要将该信息输出到 Zipkin 等服务中来收集和展示。

(3)而 hello-service 控制台输出如下:
上面四个值中的 Trace ID 和 Span ID 是 Spring Cloud Sleuth 实现分布式服务跟踪的核心。在一次服务请求链路的调用过程中,会保持并传递同一个 Trace ID,从而将整个分布于不同微服务进程中的请求跟踪信息串联起来。
- 从两个控制台输出内容可以方向,ribbon-consumer 和 hello-service 同属于一个前端服务请求来源,所以它们的 Trace ID 是相同的,处于同一条请求链路中。

5,在代码中获取相关跟踪参数信息
(1)如果我们需要在代码中获取 Sleuth 生成的相关跟踪信息,比如一个请求链路的唯一标示(TraceId)、一个工作单元的唯一标示(SpanId),是否被抽样输出(Sampled)等等。可以通过注入 brave.Tracer 对象获取:
@RestController
public class ConsumerController {
private final Logger logger = LoggerFactory.getLogger(getClass());
@Autowired
RestTemplate restTemplate;
@Autowired
Tracer tracer;
@GetMapping("/hello-consumer")
public String helloConsumer() {
logger.info("--- <call hello-consumer, TraceId={}, SpanId={}> ---",
tracer.currentSpan().context().traceId(),
tracer.currentSpan().context().spanId());
return restTemplate.getForEntity("http://HELLO-SERVICE/hello", String.class).getBody();
}
}(2)启动项目再次问 ribbon-consumer 应用的 /hello-consumer 接口,可以看到 ribbon-consumer 应用控制台输出如下:
注意:我们获取到的 TraceId 和 SpanId 值看起来和日志原来就有的值不一样,因为一个是十六机制显示,一个是十进制显示。

6,查看更多跟踪信息
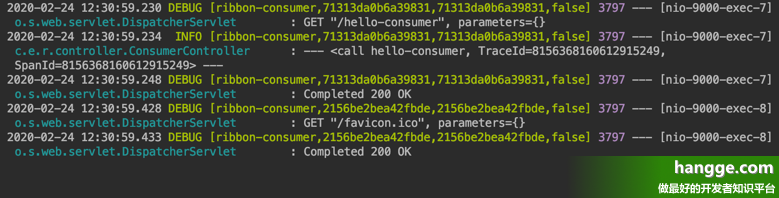
(1)为了更直观地观察跟踪信息,我们还可以在 application.properties 中增加下面的配置。通过将 Spring MVC 的请求分发日志级别调整为 DEBUG 级别,我们可以看到更多跟踪信息:
logging.level.org.springframework.web.servlet.DispatcherServlet=DEBUG(2)启动项目再次问 ribbon-consumer 应用的 /hello-consumer 接口,可以看到 ribbon-consumer 应用控制台输出如下: