NIO 是一种同步非阻塞的 I/O 模型,在 Java 1.4 中引入了 NIO 框架,对应 java.nio 包,提供了 Channel 、Selector、Buffer 等抽象。
为了支持分布式运行,Flink跟其他大数据引擎一样,采用了主从(Master-Worker)架构。Flink运行时主要包括两个组件:
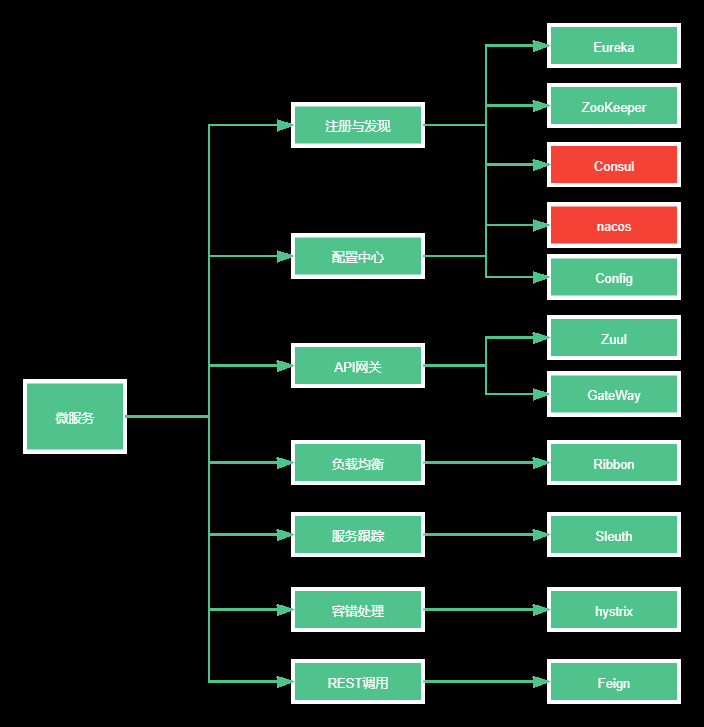
微服务跟踪(sleuth)其实是一个工具,它在整个分布式系统中能跟踪一个用户请求的过程(包括数据采集,数据传输,数据存储,数据分析,数据可视化),捕获这些跟踪数据,就能构建微服务的整个调用链的视图,这是调试和监控微服务的关键工具。
这里的数据库为本地数据库test,用户名和密码改成自己的
Bid 到 item之间简单关联,先不考虑其他情况。
在流处理中,时间是一个非常核心的概念,是整个系统的基石。我们经常会遇到这样的需求:给定一个时间窗口,比如一个小时,统计时间窗口内的数据指标。那如何界定哪些数据将进入这个窗口呢?在窗口的定义之前,首先需要确定一个作业使用什么样的时间语义。
ArrayList和Vector都是基于存储元素的Object[] array来实现的,它们会在内存中开辟一块连续的空间
但是Flink依然选择了重新开发了自己的序列化框架,因为序列化和反序列化将关乎整个流处理框架各方面的性能,对数据类型了解越多,可以更早地完成数据类型检查,节省数据存储空间。
线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。
关键词:Socket、ServerSocket、DatagramPacket、DatagramSocket
日志数据存在elasticsearch中,索引为event_YYYYMMdd,logstash获取数据转发kafka,业务消费有去重机制。